Zpět
Anotovaná literatura k PHD studiu
 Content-Based Information Retrieval in general
Content-Based Information Retrieval in general
Image Retrieval
- Rui, Huang, Chang: Image Retrieval: Current Techniques, Promising Directions, and Open Issues. Journal of Visual Communication and Image Representation, Volume 10, Issue 1, 1999.
- Veltkamp, Tanase: Content-Based Image Retrieval Systems: A Survey. 2000
 Smeulders, Worring, Santini, Gupta, Jain: Content-Based Image Retrieval at the End of the Early Years. 2000.
Smeulders, Worring, Santini, Gupta, Jain: Content-Based Image Retrieval at the End of the Early Years. 2000.- Datta, Li, Wang: Content-Based Image Retrieval - Approaches and Trends of the New Age. MIR’05
- Datta, Joshi, Li, Wang: Image retrieval: Ideas, influences, and trends of the new age. ACM Computation Surveys, 2008.
- Kherfi, Ziou, Bernardi: Image Retrieval From the World Wide Web: Issues, Techniques, and Systems. ACM computing surveys, 2004.
- Mueller, Deselaers: Image Retrieval. Tutorial TrebleCLEF Summer School 2009.
- Alemu, Koh, Ikram, Kim: Image Retrieval in Multimedia Databases: A Survey. Int. Conf. on Intelligent Information Hiding and Multimedia Signal Processing
- Enser: The evolution of visual information retrieval. Journal of Information Science, 2008. (plný text článku)
- Online book: Image Search Engines: An Overview
Semantic gap
- Hare, Lewis, Enser, Sandom: Mind the Gap: Another look at the problem of the semantic gap in image retrieval. 2006
- Guan, Antani, Long, Thoma: Bridging the semantic gap using ranking svm for image retrieval. 2009
- Liu, Zhang, Lu, Ma: A survey of content-based image retrieval with high-level semantics. 2006.
- Jain, Sinha: Content Without Context is Meaningless. MM 2010.
- Eickhoff, Li, de Vries: Exploiting User Comments for Audio-Visual Content Indexing and Retrieval. ECIR 2013
- Enser, Sandom: Towards a Comprehensive Survey of the Semantic Gap in Visual Image Retrieval. CIVR 2003: 291-299 (plný text článku)
- Enser, Sandom, Lewis: Surveying the Reality of Semantic Image Retrieval. VISUAL 2005: 177-188 (plný text článku)
User needs
- Armitage, Enser: Analysis of User Need in Image Archives. Journal of Information Science, 1997. Placené.
Existing image search systems
- IBM QBIC: Ashley, Flickner, Hafner, Lee, Niblack, Petkovic: The Query By Image Content (QBIC) System. SIGMOD 1995
- SIMPLIcity: Wang, Li, Wiederhold: SIMPLIcity: Semantics-Sensitive Integrated Matching for Picture LIbraries. IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 23, no. 9, pp. 947-963, 2001.
- Web-WISE: Wei, Li, Sethi: Web-WISE: compressed image retrieval over the web . Multimedia Information Analysis and Retrieval, 1998.
- Cortina: Quack, Monich, Thiele, Manjunath: Cortina: A System for Large-scale, Content-based Web Image Retrieval. ACM Multimedia 2004.
- MUFIN: Batko, Falchi, Lucchese, Novak, Perego, Rabitti, Sedmidubsky, Zezula: Building a web-scale image similarity search system. Multimedia Tools and Applications 2010.
- www.MMRetrieval.net: Zagoris, Arampatzis, Chatzichristofis: www.MMRetrieval.net: A Multimodal Search Engine. SISAP 2010.
Descriptors
Modalities, similarity measures
Indexing
Hashing, LSH
LSH: Theoretical papers
LSH: Theory + experiments
- Andoni, Indyk: Near-Optimal Hashing Algorithms for Approximate Nearest Neighbor in High Dimensions. COMMUNICATIONS OF THE ACM January 2008/Vol. 51, No. 1.
- Gionis, Indyk, Motwani: Similarity Search In High Dimensions via Hashing. VLDB'99.
- Lv, Josephson, Wang, Charikar, Li: Multi-Probe LSH: Efficient Indexing for High-Dimensional Similarity Search. VLDB'07.
- Dong, Wang, Josephson, Charikar, Li: Modeling LSH for Performance Tuning. CIKM'08.
"LPT" (Locality Preserving Transformations) - LSH principles for general metric spaces
Query expansion
- Natsev, Haubold, Tesic, Xie, Yan: Semantic concept-based query expansion and re-ranking for multimedia retrieval. ACM Multimedia 2007
- Pinto, Pérez-Sanjulián: Automatic query expansion and word sense disambiguation with
long and short queries using WordNet under vector model. 2008. (plný text článku)
- Gong, Cheang,Hou U: Multi-term Web Query Expansion Using WordNet. 2006. (plný text článku)
- Gong, Cheang,Hou U: Web Query Expansion by WordNet. 2005. (plný text článku)
- Deng, Dong, Socher, Li, Li, Fei-Fei: ImageNet: A Large-Scale Hierarchical Image Database. 2009. (plný text článku)
- Harris, Srinivasan: Comparing Crowd-Based, Game-Based, and Machine-Based Approaches in Initial Query and Query Refinement Tasks. 495-506
Ranking, combining metric spaces
Information fusion
- Kludas, Bruno, Marchand-Maillet: Information Fusion in Multimedia Information Retrieval. 2008
- Zhou, Depeursinge, Muller: Information Fusion for Combining Visual and Textual Image Retrieval. Pattern Recognition 2010
- Moulin, Largeron, Gery: Impact of Visual Information on Text and Content Based Image Retrieval. 2010
- Clinchant, Ah-Pine, Csurka: Semantic Combination of Textual and Visual Information in Multimedia Retrieval. ICMR 2011
- Park, Nang: Content Based Web Image Retrieval System Using Both MPEG-7 Visual Descriptors and Textual Information. MMM 2007
- He, Xiong, Yang, Park: Using Multi-Modal Semantic Association Rules to fuse keywords and visual features automatically for Web image retrieval. Information Fusion 2011
- Depeursinge, Müller: Fusion Techniques for Combining Textual and Visual Information Retrieval. Chapter 6 of ImageCLEF Experimental Evaluation in Visual Information Retrieval, Springer 2010
- Arampatzis, Zagoris, Chatzichristofis: Fusion vs. Two-Stage for Multimodal Retrieval. ECIR 2011
- Kokar, Tomasik, Weyman: Formalizing classes of information fusion systems. Information Fusion 2004
- Multimedia Information Retrieval - keynote by Stephane Marchand-Maillet, 2012
Combining metric spaces
Some kind of dynamic aggregation
- Tung, Zhang, Koudas, Ooi: Similarity Search: A Matching Based Approach. VLDB 06
- Bustos, Skopal: Dynamic Similarity Search in MultiMetric Spaces. MIR 2006
- Bustos, Keim, Saupe, Schreck, Vranic: Using Entropy Impurity for Improved 3D Object Similarity Search. ICME 2004
- Bustos, Keim, Saupe, Schreck, Vranic: Automatic Selection and Combination of Descriptors
for Effective 3D Similarity Search. ISMSE 04
Query results clustering
- Ji, Yao, Liu, Wang, Xu. A Novel Retrieval Refinement and Interaction Pattern by Exploring Result Correlations for Image Retrieval. 2008
- Chen, Wang, Krovetz. CLUE: Cluster-Based Retrieval of Images by Unsupervised Learning. IEEE Transactions on Image Processing, vol. 14, no. 8, August 2005
- Jia, Wang, Zhang, Hua. Finding Image Exemplars Using Fast Sparse Affinity Propagation. Proceeding of the 16th ACM international conference on Multimedia, 2008.
- Li, Dai, Xu, Er. Multilabel Neighborhood Propagation for Region-Based Image Retrieval. IEEE Transactions on Image Processing, 2007.
Query results reordering/ranking
- Arampatzis, Zagoris, Chatzichristofos. Dynamic Two-Stage Image Retrieval from Large Multimodal Databases. ECIR 2011
- Ambai, Yoshida. Multiclass VisualRank: Image Ranking Method in Clustered Subsets Based on Visual Features. SIGIR 09
- Jing, Baluja. VisualRank: Applying PageRank to Large-Scale Image Search. IEEE TRANSACTIONS ON PATTERN ANALYSIS AND MACHINE INTELLIGENCE, November 2008
- Jing, Baluja. PageRank for Product Image Search. WWW 2008, Beijing, China.
- Yiu, Mamoulis: Multi-dimensional top-k dominating queries. VLDB Journal 2009.
- Park, Baek, Lee: A Ranking Algorithm Using Dynamic Clustering for Content-Based Image Retrieval, 2002.
- Park, Baek, Lee: Majority Based Ranking Approach in Web Image Retrieval, CIVR 2003.
- Joyce M. dos Santos, Joao M. B. Cavalcanti, Patricia Correia Saraiva, Edleno Silva de Moura: Multimodal Re-ranking of Product Image Search Results. 62-73
- Thollard, Quénot: Content-Based Re-ranking of Text-Based Image Search Results. ECIR 2013, 618-629
Other
Relevance feedback
Understanding relevance
Basic approaches in general
Relevance feedback in image retrieval
- Ishikawa, Subramanya, Faloutsos: MindReader: Querying databases through multiple examples. VLDB 98.
- Rui, Huang, Ortega, Mehrotra: Relevance Feedback: A Power Tool in Interactive Content-Based Image Retrieval. IEEE Trans. Circuits and Systems for Video Technology, 8(5):644–655, 1998.
- Zhou, Huang: Relevance feedback in image retrieval: A comprehensive review. 2002.
- Shen, Jiang, Tan, Huang, Zhou: Speed up interactive image retrieval. 2008.
- Huiskes, Lew: Performance Evaluation of Relevance Feedback Methods. CIVR’08.
- Wu, Faloutsos, Sycara, Payne: FALCON: Feedback Adaptive Loop for Content-Based Retrieval. VLDB 2000.
- Razente, Barioni, Traina, Traina: Aggregate Similarity Queries in Relevance Feedback Methods for Content-based Image Retrieval. SAC’08.
- Hua, Yu, Liu: Query Decomposition: A Multiple Neighborhood Approach to Relevance Feedback Processing in Content-based Image Retrieva. ICDE’06
- Vu, Cheng, Hua: Image Retrieval in Multipoint Queries. 2008.
Image annotation
Surveys
Model-based approaches
Search-based approaches
Text-based approaches
- Eickhoff, Li, de Vries: Exploiting User Comments for Audio-Visual Content Indexing and Retrieval. ECIR 2013
- Noel, Peterson: Context-Driven Image Annotation Using ImageNet. 26th International Florida Artificial Intelligence Research Society Conference, 2013
- Du, Rau, Huang, Chen: Improving the quality of tags using state transition on progressive image search and recommendation system. SMC 2012
- Sun, Bhowmick, Chong: Social image tag recommendation by concept matching. ACM Multimedia 2011
- Lux, Pitman, Marques: Can Global Visual Features Improve Tag Recommendation for Image Annotation? Future Internet 2010
Annotation refinement techniques
- Belém, Martins, Almeida, Gonçalves: Exploiting Novelty and Diversity in Tag Recommendation. ECIR 2013
- McParlane, Jose: Exploiting Time in Automatic Image Tagging. ECIR 2013, 520-531
- Kern, R.; Granitzer, M.; Pammer, V. Extending Folksonomies for Image Tagging. In Proceedings of 9th International Workshop on Image Analysis for Multimedia Interactive Services, Klagenfurt, Austria, 7–9 May 2008.
- Graham, R.; Caverlee, J. Exploring Feedback Models in Interactive Tagging. In Proceedings of
the 2008 IEEE/WIC/ACM International Conference on Web Intelligence and Intelligent Agent
Technology, Sydney, Australia, 9–12 December 2008; IEEE Computer Society: Washington, DC,
USA, 2008; pp. 141–147.
Domain specific solutions
Manual annotation, ground truth acquisition
- Ames, Naaman: Why we tag: motivations for annotation in mobile and online media. In: SIGCHI 2007 (2007)
Resources
Other
- Deselaers, Ferrari: Visual and semantic similarity in ImageNet. Computer Vision and Pattern Recognition (CVPR), 2011.
- Heesch, Yavlinsky, Rüger: NNk Networks and Automated Annotation for Browsing Large Image Collections from the World Wide Web. Multimedia 2006.
- Noah, Ali, Alhadi, Kassim: Going Beyond the Surrounding Text to Semantically Annotate and Search Digital Images. ACIIDS 2010.
- Nowak, Huiskes: New Strategies for Image Annotation: Overview of the Photo Annotation Task at ImageCLEF 2010. ImageCLEF 2011.
- Barnard, Duygulu, Forsyth, Freitas, Blei, Jordan: Matching Words and Pictures. 2003. (plný text článku)
- Wang, Zhang, Jing, Ma: Annosearch: Image auto-annotation by search. CVPR 2006. (plný text článku)
- Enser, Sandom, Lewis: Automatic Annotation of Images from the Practitioner Perspective. CIVR 2005: 497-506 (plný text článku)
- Sinha, Jain: Semantics in Digital Photos: A Contenxtual Analysis. In Proceedings of 'ICSC
'08: The 2008 IEEE International Conference on Semantic Computing, Santa Clara, CA, USA,
4–7 August 2008; IEEE Computer Society: Washington, DC, USA, pp. 58–65.
Summarization of image collections
- Rudinac, Larson, Hanjalic: Learning Crowdsourced User Preferences for Visual Summarization of Image Collections. IEEE Transactions on Multimedia, 2013
- Metze, Ding, Younessian, Hauptmann: Beyond audio and video retrieval: topic-oriented multimedia summarization. International Journal of Multimedia Information Retrieval, 2013
- Tan, Song, Liu, Xie: ImageHive: Interactive Content-Aware Image Summarization. IEEE Computer Graphics and Applications, 2012
- Zheng, Herranz, Jiang: Flexible navigation in smartphones and tablets using scalable storyboards. ICMR 2013
- Liu, Wang, Sun, Zheng, Tang, Shum: Picture Collage. IEEE Transactions on Multimedia, 2009
- Ekhtiyar, Sheida, Amintoosi: Picture Collage with Genetic Algorithm and Stereo vision. CoRR, 2012
- Zhang, Huang: Hierarchical Narrative Collage For Digital Photo Album. Computer Graphics Foru, 2012
- Nenkova, McKeown: A Survey of Text Summarization Techniques. Mining Text Data, 2012
Ontologies
Evaluation
Building ground truth
- Yao, Yang, Zhu: Introduction to a Large-Scale General Purpose Ground Truth Database: Methodology, Annotation Tool and Benchmarks. 2007. (plný text článku)
- Muller, Geissbuhler, Marchand–Maillet, Clough. Benchmarking Image Retrieval Applications. 2004. (plný text článku)
- Alonso, Mizzaro: Can we get rid of trec assessors? Using mechanical turk for relevance assessment. In: SIGIR 2009 Workshop on the Future of IR Evaluation (2009)
Performance metrics
Query Language
- Amato, Mainetto, Savino: A Query Language for Similarity-based Retrievla of Multimedia Data. Advances in Databases and Information Systems 1997.
- Adali, Bonatti, Sapino, Subrahmanian: A multi-similarity algebra. SIGMOD 98
- Town, Sinclair: Ontological Query Language for Content Based Image Retrieval. ANSS’03.
- Döller, Kosch, Wolf, Gruhne: Towards an MPEG-7 Query Language. SITIS 2006
- Mamou, Mass, Shmueli-Scheuer, Sznajder: A Query Language for Multimedia Content. Sigir’07.
- Gruhne, Tous, Delgado, Doeller, Kosch: MP7QF: An MPEG-7 Query Format. 2007.
- Guliato, de Melo, Rangayyan, Soares: POSTGRESQL-IE: An Image-handling Extension for PostgreSQL. Journal of Digital Imaging, Vol 22, No 2, 2009
- Pein, Lu, Renz: An Extensible Query Language for Content Based Image Retrieval based on Lucene. 2008
- Döller, Tous, Gruhne, Yoon, Sano, Burnett: The MPEG Query Format: Unifying Access to Multimedia Retrieval Systems. IEEE MultiMedia, 2008.
- Barioni, Razente, Traina, Traina: Seamlessly integrating similarity queries in SQL. Software - Practice and Experience, 2009
- Silva, Aref, Larson, Pearson, Ali: Similarity queries: their conceptual evaluation, transformations, and processing. VLDB Journal, June 2013
Other interesting papers and ideas
Datta, Li, Wang: Content-Based Image Retrieval - Approaches and Trends of the New Age. MIR’05

plný text článku,
bibtex
@inproceedings{Datta:2005:CIR:1101826.1101866,
author = {Datta, Ritendra and Li, Jia and Wang, James Z.},
title = {Content-based image retrieval: approaches and trends of the new age},
booktitle = {Proceedings of the 7th ACM SIGMM international workshop on Multimedia information retrieval},
series = {MIR '05},
year = {2005},
isbn = {1-59593-244-5},
location = {Hilton, Singapore},
pages = {253--262},
numpages = {10},
url = {http://doi.acm.org/10.1145/1101826.1101866},
doi = {http://doi.acm.org/10.1145/1101826.1101866},
acmid = {1101866},
publisher = {ACM},
address = {New York, NY, USA},
keywords = {annotation, content-based image retrieval},
}
Pěkný úvod do CBIR (co je obtížnější ve strovnání s text retrieval), že je to důležité zkoumat
(dokumentováno nárustem publikací v této oblasti za poslední roky; 120 užitečných citací!). Obsahuje stručnou diskuzi
o používaných deskriptorech, shrnutí základních přístupů k CBIR (semantics-sensitive approach,
use of hierarchical perceptual grouping
of primitive image features and their inter-relationships to
characterize structure; Clustering has
been applied to image retrieval to help improve interface
design, visualization, and result pre-processing). Annotation and Concept Detection
- velmi přínosné, pokud se podaří anotaci udělat, to je ale velmi obtížné,
zatím se to zvládá jen pro hrubé zařazení do kategorií; pomoci může učení
z předchozích výsledků. Velmi dobré zmapování základních přístupů
Relevance feedback. Diskuze o HW urychlení a vhodných uživatelských
rozhraních.
- The trends in these graphs indicate a roughly exponential growth in interest in image
retrieval and closely related topics. We also note that growth in the field has been particularly
strong over the last five years, spanning new techniques, new support systems, and diverse
application domains. Yet, a brief scanning of about 300 relevant papers published in the
last five years revealed that less than 20% were concerned with applications or real-world
systems. This may not be a cause for concern, since the theoretical foundation (if any
such exists) behind how we humans interpret images is still an open problem. But then, with
hundreds of different approaches proposed so far, and no consensus reached on any, it is rather
optimistic to believe that we will chance upon a reliable one in the near future. Instead, it may make
more sense to build systems that are useful, even if their use is limited to specific domains.
A way to see this is that natural language interpretation is an unsolved problem, yet text-based
search engines have proved very useful.
- Relevance feedback (RF) is a query modification technique, originating in information retrieval, that
attempts to capture the user’s precise needs through iterative feedback and query refinement....
One problem with RF is that after every round of user interaction, usually the top results with respect to the
query have to be recomputed using a modified similarity measure. A way to speed up this nearest-neighbor search has
been proposed in [109]. Another issue is the user’s patience in supporting multi-round feedbacks. A way to reduce the
user’s interaction is to incorporate logged feedback history into the current query [41]. History of usage
can also help in capturing the relationship between high level semantics and low level features [36].
We can also view RF as an active learning process, where the learner chooses an appropriate
subset for feedback from the user in each round based on her previous rounds of feedback, instead
of choosing a random subset. Active learning using SVMs was introduced into the field of image
retrieval in [95]. Extensions to the active learning process have also been proposed [31, 37]. ...
With the increase in popularity of region-based image retrieval [12, 104], attempts have been
made to incorporate the region factor into RF using query point movement and support vector
machines [49, 50]. A tree-structured self-organizing map has been used as an underlying technique
for RF [58] in a content-based image retrieval system [57]. Probabilistic approaches have been
taken in [21, 91, 100]. A clustering based approach to RF incorporating the user’s perception
in case of complex queries has been studied in [53]. In [39], manifold learning on the user’s feedback
based on geometric intuitions about the underlying feature space is proposed. While most RF algorithms
proposed deal with a two-class problem, i.e., relevant or irrelevant images, another way of looking
at RF is to consider multiple relevant and irrelevant groups of images using an appropriate user
interface [40, 79, 118]. For example, if the user is looking for cars, then she can highlight
groups of blue cars and red cars as relevant examples, since it may not be possible to
represent the concept car uniformly in any low level feature space. Yet another deviation from
norm is the use of multilevel relevance scores to incorporate the relative degrees of relevance
of certain images to the user’s query [108].
Datta, Joshi, Li, Wang: Image retrieval: Ideas, influences, and trends of the new age. ACM Computation Surveys, 2008.
plný text článku,
bibtex
@article{Datta:2008:IRI:1348246.1348248,
author = {Datta, Ritendra and Joshi, Dhiraj and Li, Jia and Wang, James Z.},
title = {Image retrieval: Ideas, influences, and trends of the new age},
journal = {ACM Comput. Surv.},
volume = {40},
issue = {2},
month = {May},
year = {2008},
issn = {0360-0300},
pages = {5:1--5:60},
articleno = {5},
numpages = {60},
url = {http://doi.acm.org/10.1145/1348246.1348248},
doi = {http://doi.acm.org/10.1145/1348246.1348248},
acmid = {1348248},
publisher = {ACM},
address = {New York, NY, USA},
keywords = {Content-based image retrieval, annotation, learning, modeling, tagging},
}
Rozšířená verze předchozího. V úvodu stručné shrnutí survey Smeulders00.
Kherfi, Ziou, Bernardi: Image Retrieval From the World Wide Web: Issues, Techniques, and Systems. ACM computing surveys, 2004.
plný text článku,
bibtex
@article{Kherfi:2004:IRW:1013208.1013210,
author = {Kherfi, M. L. and Ziou, D. and Bernardi, A.},
title = {Image Retrieval from the World Wide Web: Issues, Techniques, and Systems},
journal = {ACM Comput. Surv.},
volume = {36},
issue = {1},
month = {March},
year = {2004},
issn = {0360-0300},
pages = {35--67},
numpages = {33},
url = {http://doi.acm.org/10.1145/1013208.1013210},
doi = {http://doi.acm.org/10.1145/1013208.1013210},
acmid = {1013210},
publisher = {ACM},
address = {New York, NY, USA},
keywords = {Image-retrieval, World Wide Web, crawling, feature extraction and selection, indexing, relevance feedback, search, similarity},
}
Proč potřeba web image search. Applications - různé kategorie, hezky rozebrané. Jaké služby
by lidé od web search engine očekávali: query-based retrieval, browsing, summary of a set of images.
Dále popis několika existujících image search systémů, které většinou kombinují text a visual search.
Dobrý přehled zdrojů a funkčnosti (charakteristika, které deskriptory, jaké dotazy podporuje).
V další sekci se řeší návrh Web image search engine, a to konkrétně tyto části:
data gathering, the identification and the estimation of image descriptors, similarity and matching,
indexing, query specification, retrieval and refinement, Web coverage, and performance evaluation.
Ohledně text search pěkný přehled toho, které kusy stránky který systém využívá. Odkaz na článek,
který řeší, jak poznat relevantní slova ve stránce. Dále dobrý přehled možností query formulation.
Doporučení používat text i image. V další části zadefinován evaluation test-bed a metriky porovnávání
systémů včetně netradičních jako ease of use, numer of iterations. Nakonec různé open issues
- např. pochopení potřeb uživatele, jsou tam nějaké citace, i když starších článků.
- It is very useful for a Web image search system to offer an image taxonomy based on subjects such
as art and culture, sports, world regions, technology etc. ... WebSeek offers an online catalog.
- page zero problem: finding a good query image to initiate the retrieval. To avoid falling into
this problem, the system must provide the user with a set of candidate images that are representative of the entire visual
content of the Web, for example, by choosing an image from each category. If none of these images is appropriate, the user
should be allowed to choose to view more candidate images. Another solution to the page zero problem, used in the PicToSeek
system, involves asking the user to provide an initial image; however, it is not always easy for users to find such an image.
ImageRover and WebSeek ask the user to introduce a textual query at the beginning, after which both textual and visual
refinement are possible. In Kherfi et al. [2003b], we showed that the use of a positive example together with a negative example
can also help to mitigate the page zero problem.
Alemu, Koh, Ikram, Kim: Image Retrieval in Multimedia Databases: A Survey. Int. Conf. on Intelligent Information Hiding and Multimedia Signal Processing
plný text článku,
bibtex
@inproceedings{DBLP:conf/iih-msp/AlemuKIK09,
author = {Yihun Alemu and
Jong-bin Koh and
Muhammad Ikram and
Dong-Kyoo Kim},
title = {Image Retrieval in Multimedia Databases: A Survey},
booktitle = {IIH-MSP},
year = {2009},
pages = {681-689},
ee = {http://doi.ieeecomputersociety.org/10.1109/IIH-MSP.2009.159},
crossref = {DBLP:conf/iih-msp/2009},
bibsource = {DBLP, http://dblp.uni-trier.de}
}
@proceedings{DBLP:conf/iih-msp/2009,
editor = {Jeng-Shyang Pan and
Yen-Wei Chen and
Lakhmi C. Jain},
title = {Fifth International Conference on Intelligent Information
Hiding and Multimedia Signal Processing (IIH-MSP 2009),
Kyoto, Japan, 12-14 September, 2009, Proceedings},
booktitle = {IIH-MSP},
publisher = {IEEE Computer Society},
year = {2009},
isbn = {978-1-4244-4717-6},
ee = {http://ieeexplore.ieee.org/xpl/mostRecentIssue.jsp?punumber=5337074},
bibsource = {DBLP, http://dblp.uni-trier.de}
}
Přehled přístupů - text search, CBIR, ontology-based image retrieval. Nejde to moc do hloubky,
ale pro rychlý přehled dobré, dá se citovat pro úvod do text-based a content-based image search.
Mueller, Deselaers: Image Retrieval. Tutorial TrebleCLEF Summer School 2009.
web s prezentacemi tutorialu
Hare, Lewis, Enser, Sandom: Mind the Gap: Another look at the problem of the semantic gap in image retrieval. 2006
plný text článku,
bibtex
@article{Hare_2006,
title={Mind the gap: another look at the problem of the semantic gap in image retrieval},
volume={6073},
url={http://link.aip.org/link/PSISDG/v6073/i1/p607309/s1&Agg=doi},
number={1},
journal={Proceedings of SPIE},
publisher={Spie},
author={Hare, J S},
year={2006},
pages={607309--607309-12}
}
Uvažuje sémantické dotazy "Najdi obrázek, kde je vlk ve sněhu na silnici v Atlantě z roku 2000".
Semantic gap rozdělen na několik částí: obrázek => reprezentace => objekty => klíčová slova => sémantika.
Popsány existující přístupy k automatické anotaci klíčovými slovy - to označují jako přístup
zdola. Přístup shora je přes ontologie.
Guan, Antani, Long, Thoma: Bridging the semantic gap using ranking svm for image retrieval. 2009
plný text článku,
bibtex
@INPROCEEDINGS{5193057,
author={Haiying Guan and Antani, S. and Long, L.R. and Thoma, G.R.},
booktitle={Biomedical Imaging: From Nano to Macro, 2009. ISBI '09. IEEE International Symposium on},
title={Bridging the semantic gap using Ranking SVM for image retrieval},
year={2009},
month={28 2009-july 1},
volume={},
number={},
pages={354 -357},
keywords={X-ray imaging;content-based image retrieval;image features;ranking SVM;ranking support vector machine algorithm;semantic concepts;spine;supervised learning algorithm;vertebra shape retrieval;bone;diagnostic radiography;image retrieval;learning (artificial intelligence);medical image processing;support vector machines;},
doi={10.1109/ISBI.2009.5193057},
ISSN={1945-7928},
}
Pro kolekci rentgenových obrázků páteře aplikují učící algoritmus založený na SVM,
inovací je, že se nehledají kategorie, ale optimální ranking. Stručný, jasný a výstižný
článek, pro specializované kolekce je to asi dobré řešení.
Liu, Zhang, Lu, Ma: A survey of content-based image retrieval with high-level semantics. 2006.
plný text článku,
bibtex
@article{Liu2007262,
title = "A survey of content-based image retrieval with high-level semantics",
journal = "Pattern Recognition",
volume = "40",
number = "1",
pages = "262 - 282",
year = "2007",
note = "",
issn = "0031-3203",
doi = "DOI: 10.1016/j.patcog.2006.04.045",
url = "http://www.sciencedirect.com/science/article/pii/S0031320306002184",
author = "Ying Liu and Dengsheng Zhang and Guojun Lu and Wei-Ying Ma",
keywords = "Content-based image retrieval",
keywords = "Semantic gap",
keywords = "High-level semantics",
keywords = "Survey"
}
Survey přístupů k řešení Semantic gap. Identifikují pět hlavních přístupů: (1) using object ontology to define high-level concepts;
(2) using machine learning methods to associate low-level features with query concepts;
(3) using relevance feedback to learn users’ intention;
(4) generating semantic template to support high-level image retrieval;
(5) fusing the evidences from HTML text and the visual content of images for WWW image retrieval.
V úvodní části velmi srozumitelně popsány metody segmentace a extrakce deskriptorů.
Object ontology: nasegmentované úseky se popíší pomocí vlastností deskriptorů, třeba světle modrý,
jednolitý, umístěný nahoře. Na další úrovni se těmto vlastnostem přiřadí pojem obloha. Způsoby pojmenování
barev, asi se to zvlášť hodí na vyhledávání v uměleckých kolekcích.
Machine learning: supervised - účelem je naučit systém správně kategorizovat či pojmenovávat; unsuperised
- snaží se podchytit, jak jsou data organizována/clusterována. Supervised přístupy: SVM, Bayesian classification,
neuronové sítě, rozhodovací stromy, bootstrapping. Rozhodovací stromy někdo používá pro relevance feedback
(rozhodování relevantní/nerelevantní). Typickým příkladem unsupervised learning je image clustering (metody
k-means clustering, Normalized cut, CLUE; locality preserving clustering). Učení se může používat pro object recognition.
Relevance feedback: online metoda, hlavní přístupy: změna vah, posouvání query point (často využívá Rocchio vzorec). Obě tyto
metody používají nearest-neighbor sampling. Při určování změněného dotazu se často používají machine learning techniques.
Semantic templates: mapování mezi sémantickými koncepty a nízkoúrovňovými deskriptory. Semantic template obvykle definována
jako reprezentativní vlastnost pro daný koncept odvozená ze vzorových objektů. Může se vytvářet během relevance feedback.
Web image retrieval: má specifické vlastnosti, může využívat další informace získané z webové stránky (URL, title, alt, description,
hyperlinks).
Článek dále obsahuje obsáhlou diskuzi o testovacích datech, zejména o výhodách a nevýhodách nejpoužívanější
kolekce Corel. Dále se řeší vhodné slovníky pro sémantické koncepty. Nakonec řeší evaluační metody: precision, recall,
jejich poměry, poměr ku scope, rank.
V další sekci zmiňují potřebu dotazovacího jazyka, popisují několik existujících návrhů, které jsou ale všechny
sémantické. Také se stručně věnují indexovacím strukturám a upozorňují, že často nejsou specializované na
vlastnosti obrázků (existují i některé, které se o to snaží).
Jain, Sinha: Content Without Context is Meaningless. MM 2010.
plný text článku,
bibtex
@inproceedings{Jain:2010:CWC:1873951.1874199,
author = {Jain, Ramesh and Sinha, Pinaki},
title = {Content without context is meaningless},
booktitle = {Proceedings of the international conference on Multimedia},
series = {MM '10},
year = {2010},
isbn = {978-1-60558-933-6},
location = {Firenze, Italy},
pages = {1259--1268},
numpages = {10},
url = {http://doi.acm.org/10.1145/1873951.1874199},
doi = {http://doi.acm.org/10.1145/1873951.1874199},
acmid = {1874199},
publisher = {ACM},
address = {New York, NY, USA},
keywords = {content, context, exif, image, mobile, perception, search},
}
Kritika současného trendu výzkumu - děláme content-based, kašleme na context, přitom
v praxi se používá zrovna context a to naše ne. Příliš mnoho problémů se snažíme řešit
strojovým učením ("Machine Learning Hammer"). Zmiňují otázku, jestli současný výzkum
vůbec řeší ten správný problém (k čemu se používá které medium, jaké informace z něj
jsou podstatné...). Multimedia content problem má být "perception problem", kde je
nutno vzít do úvahy prostředí, medium a příjemce. Hezké shrnutí problematiky Image understanding,
proč je to složité a proč to jde se současným přístupem dělat jen pro omezené domény.
Lidské vnímání je hodně založeno na context - naší znalosti prostředí a zkušenosti.
V počítačovém zpracování může context pomoci ke zúžení prohledávaného prostoru, což
je zásadní, protože jinak je ten prostor příliš velký a různorodý. To je problém možná
ani ne výkonnostní, ale zejména je tam příliš mnoho šumu.
Tipy na konkrétní využití context: EXIF metadata - z doby expozice se třeba dá odhadovat,
zda je fotka denní/noční, venku/vevnitř apod., z ohniskové délky se dá odhadovat velikost.
Eickhoff, Li, de Vries: Exploiting User Comments for Audio-Visual Content Indexing and Retrieval. ECIR 2013
plný text článku,
bibtex
@inproceedings{DBLP:conf/ecir/EickhoffLV13,
author = {Carsten Eickhoff and
Wen Li and
Arjen P. de Vries},
title = {Exploiting User Comments for Audio-Visual Content Indexing
and Retrieval},
booktitle = {ECIR},
year = {2013},
pages = {38-49},
ee = {http://dx.doi.org/10.1007/978-3-642-36973-5_4},
crossref = {DBLP:conf/ecir/2013},
bibsource = {DBLP, http://dblp.uni-trier.de}
}
@proceedings{DBLP:conf/ecir/2013,
editor = {Pavel Serdyukov and
Pavel Braslavski and
Sergei O. Kuznetsov and
Jaap Kamps and
Stefan M. R{\"u}ger and
Eugene Agichtein and
Ilya Segalovich and
Emine Yilmaz},
title = {Advances in Information Retrieval - 35th European Conference
on IR Research, ECIR 2013, Moscow, Russia, March 24-27,
2013. Proceedings},
booktitle = {ECIR},
publisher = {Springer},
series = {Lecture Notes in Computer Science},
volume = {7814},
year = {2013},
isbn = {978-3-642-36972-8},
ee = {http://dx.doi.org/10.1007/978-3-642-36973-5},
bibsource = {DBLP, http://dblp.uni-trier.de}
}
Didn't read in detail, but the main idea is pretty simple and interesting at the same time: use a new modality
for video search - tags extracted from YouTube comments. Some time series analysis and filtering by Wikipedia are used.
Noel, Peterson: Context-Driven Image Annotation Using ImageNet. 26th International Florida Artificial Intelligence Research Society Conference, 2013
plný text článku,
bibtex
@inproceedings{DBLP:conf/flairs/NoelP13,
author = {George E. Noel and
Gilbert L. Peterson},
title = {Context-Driven Image Annotation Using ImageNet},
booktitle = {FLAIRS Conference},
year = {2013},
ee = {http://www.aaai.org/ocs/index.php/FLAIRS/FLAIRS13/paper/view/5892},
crossref = {DBLP:conf/flairs/2013},
bibsource = {DBLP, http://dblp.uni-trier.de}
}
@proceedings{DBLP:conf/flairs/2013,
editor = {Chutima Boonthum-Denecke and
G. Michael Youngblood},
title = {Proceedings of the Twenty-Sixth International Florida Artificial
Intelligence Research Society Conference, FLAIRS 2013, St.
Pete Beach, Florida. May 22-24, 2013},
booktitle = {FLAIRS Conference},
publisher = {AAAI Press},
year = {2013},
ee = {http://www.aaai.org/Library/FLAIRS/flairs13contents.php},
bibsource = {DBLP, http://dblp.uni-trier.de}
}
Annotate images using visual content and context = keywords from title/surrounding page/whatever. Use the
keywords to determine synsets from WordNet, then use appropriate ImageNet data to compare with the image
to be annotated, select the most probable synsets. Face classifier used to verify people-related concepts.
Lew, Sebe, Djeraba, Jain: Content-Based Multimedia Information Retrieval: State of the Art and Challenges. ACM 06.
plný text článku,
bibtex
@article{Lew:2006:CMI:1126004.1126005,
author = {Lew, Michael S. and Sebe, Nicu and Djeraba, Chabane and Jain, Ramesh},
title = {Content-based multimedia information retrieval: State of the art and challenges},
journal = {ACM Trans. Multimedia Comput. Commun. Appl.},
volume = {2},
issue = {1},
month = {February},
year = {2006},
issn = {1551-6857},
pages = {1--19},
numpages = {19},
url = {http://doi.acm.org/10.1145/1126004.1126005},
doi = {http://doi.acm.org/10.1145/1126004.1126005},
acmid = {1126005},
publisher = {ACM},
address = {New York, NY, USA},
keywords = {Multimedia information retrieval, audio retrieval, human-computer interaction, image databases, image search, multimedia indexing, video retrieval},
}
Jednou z hlavních výzev je Semantic gap - vyhledávání pomocí low-level deskriptorů
je vhodné jen pro některé aplikace a znalé uživatele, pro běžného uživatele
je potřeba "přeložit" deskriptory do srozumitelných pojmů. Opět zmiňuje problém
objektivních benchmarků pro srovnávání. Odkazy na různé studie, co uživatelé
potřebují.
- 2.2.2 Relevance Feedback. Beyond the one-shot queries in the early similarity-based search systems,
the next generation of systems attempted to integrate continuous feedback from the user in order
to learn more about the user query. The interactive process of asking the user a sequential set of
questions after each round of results was called relevance feedback because of its similarity to older
pure text approaches. Relevance feedback can be considered a special case of emergent semantics. Other
names have included query re?nement, interactive search, and active learning fromthe computer vision
literature. The fundamental idea behind relevance feedback is to show the user a list of candidate images,
ask the user to decide whether each image is relevant or irrelevant, and modify the parameter space,
semantic space, feature space, or classi?cation space to re?ect the relevant and irrelevant examples.
In the simplest relevance feedback method from Rocchio [1971], the idea is to move the query point
toward the relevant examples and away from the irrelevant examples. In principle, one general view
is to view relevance feedback as a particular type of pattern classi?cation in which the positive and
negative examples are found from the relevant and irrelevant labels, respectively.
Bozzon, Fraternali: Multimedia and Multimodal Information Retrieval. Search Computing, Chapter 8, Springer 2010.
plný text článku,
bibtex
@incollection {springerlink:10.1007/978-3-642-12310-8_8,
author = {Bozzon, Alessandro and Fraternali, Piero},
affiliation = {Politecnico di Milano Dipartimento di Elettronica e Informazione Piazza Leonardo da Vinci 32 20133 Milano Italy},
title = {Chapter 8: Multimedia and Multimodal Information Retrieval},
booktitle = {Search Computing},
series = {Lecture Notes in Computer Science},
editor = {Ceri, Stefano and Brambilla, Marco},
publisher = {Springer Berlin / Heidelberg},
isbn = {},
pages = {135-155},
volume = {5950},
url = {http://dx.doi.org/10.1007/978-3-642-12310-8_8},
note = {10.1007/978-3-642-12310-8_8},
year = {2010}
}
Survey k multimodal information retrieval, obsahuje hezké formulace základních problémů MIR, jednodlivé části
procesu od data acquisition po presentation. Je tam také kapitolka ke query languages.
Rui, Huang, Chang: Image Retrieval: Current Techniques, Promising Directions, and Open Issues. Journal of Visual Communication and Image Representation, Volume 10, Issue 1, 1999.
plný text článku,
bibtex
@ARTICLE{Rui99imageretrieval:,
author = {Yong Rui and Thomas S. Huang and Shih-fu Chang},
title = {Image Retrieval: Current Techniques, Promising Directions And Open Issues},
journal = {Journal of Visual Communication and Image Representation},
year = {1999},
volume = {10},
pages = {39--62}
}
Úvod do Content-Based Image Retrieval - historie, hlavní problémy. Hlavní problémy
jsou detailně rozebrány:
- visual features, jejich reprezentace (hezky popsány různé
přístupy, jak popsat barvy, ..., a jak počítat podobnost)
- indexování: jako základní přístupy uvádějí dimension reduction a potom různé stromové indexy (R-tree, k-d tree).
Jako nové přístupy zmiňují clustering a neural nets.
- state-of-the-art komerční a akademické systémy: většinou podporují něco z: random browsing, search by example,
search by sketch, search by text (including key word or speech), navigation with customized image categories.
Popis několika systémů (QBIC, MARS, WebSeek, ...)
Dále navrhují směry budoucího výzkumu: human in the loop, relevance feedback, web-oriented systems,
high-dimensional indexing, performance evaluation criterion a testbed.
Veltkamp, Tanase: Content-Based Image Retrieval Systems: A Survey. 2000.
plný text článku
bibtex
@techreport{citeulike:3430154,
abstract = {In many areas of commerce, government, academia, and hospitals, large collections of digital images are being created. Many of these collections are the product of digitizing existing collections of},
author = {Veltkamp, Remco C. and Tanase, Mirela},
citeulike-article-id = {3430154},
citeulike-linkout-0 = {http://citeseerx.ist.psu.edu/viewdoc/summary?doi=10.1.1.31.7344},
institution = {Department of Computing Science, Utrecht University},
keywords = {retrieval, survey},
posted-at = {2008-10-20 09:24:50},
priority = {2},
title = {Content-Based Image Retrieval Systems: {A} Survey},
url = {http://citeseerx.ist.psu.edu/viewdoc/summary?doi=10.1.1.31.7344},
year = {2002}
}
Popis několika desítek CBIR systémů. Jak jsou objekty popsány, jak se zadává a vyhodnocuje
dotaz, jak jsou prezentovány výsledky. U některých zmíněn a stručně popsán relevance feedback.
Smeulders, Worring, Santini, Gupta, Jain: Content-Based Image Retrieval at the End of the Early Years. 2000.
plný text článku,
bibtex
@ARTICLE{895972,
author={Smeulders, A.W.M. and Worring, M. and Santini, S. and Gupta, A. and Jain, R.},
journal={Pattern Analysis and Machine Intelligence, IEEE Transactions on}, title={Content-based image retrieval at the end of the early years},
year={2000},
month={dec},
volume={22},
number={12},
pages={1349 -1380},
keywords={accumulative features;content-based image retrieval;databases;global features;local geometry;pictures;salient points;semantic gap;semantics;sensory gap;similarity;system architecture;system engineering;use patterns;computer vision;content-based retrieval;image colour analysis;image retrieval;image segmentation;image texture;reviews;visual databases;},
doi={10.1109/34.895972},
ISSN={0162-8828},
}
Ashley, Flickner, Hafner, Lee, Niblack, Petkovic: The Query By Image Content (QBIC) System. SIGMOD 1995.
plný text článku,
bibtex
@inproceedings{Ashley:1995:QIC:223784.223888,
author = {Ashley, Jonathan and Flickner, Myron and Hafner, James and Lee, Denis and Niblack, Wayne and Petkovic, Dragutin},
title = {The query by image content (QBIC) system},
booktitle = {Proceedings of the 1995 ACM SIGMOD international conference on Management of data},
series = {SIGMOD '95},
year = {1995},
isbn = {0-89791-731-6},
location = {San Jose, California, United States},
pages = {475--},
url = {http://doi.acm.org/10.1145/223784.223888},
doi = {http://doi.acm.org/10.1145/223784.223888},
acmid = {223888},
publisher = {ACM},
address = {New York, NY, USA},
}
Wang, Li, Wiederhold: SIMPLIcity: Semantics-Sensitive Integrated Matching for Picture LIbraries. IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 23, no. 9, pp. 947-963, 2001.
plný text článku,
bibtex
@ARTICLE{Wang01simplicity:semantics-sensitive,
author = {James Z. Wang and Jia Li and Gio Wiederhold},
title = {SIMPLIcity: Semantics-Sensitive Integrated Matching for Picture LIbraries},
journal = {IEEE Transactions on Pattern Analysis and Machine Intelligence},
year = {2001},
volume = {23},
pages = {947--963}
}
Mají databázi oztříděnou do několika kategorií - textured/nontextured, graph/photograph.
Několik vlastních deskriptorů - region-based, ale pak se to spojí do jednoho globálního.
Zkoušeno na 200K obrázcích.
Wei, Li, Sethi: Web-WISE: compressed image retrieval over the web . Multimedia Information Analysis and Retrieval, 1998.
plný text článku,
bibtex
@incollection{springerlink:10.1007/BFb0016487,
author = {Wei, Gang and Li, Dongge and Sethi, I.},
affiliation = {Wayne State University Vision and Neural Network Lab. Dept. of Computer Science 48202 Detroit MI 48202 Detroit MI},
title = {Web-WISE: compressed image retrieval over the web},
booktitle = {Multimedia Information Analysis and Retrieval},
series = {Lecture Notes in Computer Science},
editor = {Ip, Horace and Smeulders, Arnold},
publisher = {Springer Berlin / Heidelberg},
isbn = {},
pages = {33-46},
volume = {1464},
url = {http://dx.doi.org/10.1007/BFb0016487},
note = {10.1007/BFb0016487},
year = {1998}
}
Systém má tři části: stahování obrázků z webu, extrakce deskriptorů a zpracování dotazu. Color a texture global
descriptors (vlastní).
Quack, Monich, Thiele, Manjunath: Cortina: A System for Large-scale, Content-based Web Image Retrieval. ACM Multimedia 2004.
plný text článku,
bibtex
@inproceedings{Quack:2004:CSL:1027527.1027650,
author = {Quack, Till and M\"{o}nich, Ullrich and Thiele, Lars and Manjunath, B. S.},
title = {Cortina: a system for large-scale, content-based web image retrieval},
booktitle = {Proceedings of the 12th annual ACM international conference on Multimedia},
series = {MULTIMEDIA '04},
year = {2004},
isbn = {1-58113-893-8},
location = {New York, NY, USA},
pages = {508--511},
numpages = {4},
url = {http://doi.acm.org/10.1145/1027527.1027650},
doi = {http://doi.acm.org/10.1145/1027527.1027650},
acmid = {1027650},
publisher = {ACM},
address = {New York, NY, USA},
keywords = {MPEG-7, WWW, association rules, clustering, large-scale, online, relevance feedback, semantics, web image retrieval},
}
3 million images. Visual features and collateral text. Search process consists of an
initial query-by-keyword or query-by-image and followed by relevance feedback on the visual appearance of the results.
Semantic relationships in the data are explored and exploited by data mining, and multiple feature
spaces are included in the search process. Uses four global MPEG7 feature descriptors for color and texture.
Batko, Falchi, Lucchese, Novak, Perego, Rabitti, Sedmidubsky, Zezula: Building a web-scale image similarity search system. Multimedia Tools and Applications 2010.
plný text článku,
bibtex
@article {springerlink:10.1007/s11042-009-0339-z,
author = {Batko, Michal and Falchi, Fabrizio and Lucchese, Claudio and Novak, David and Perego, Raffaele and Rabitti, Fausto and Sedmidubsky, Jan and Zezula, Pavel},
affiliation = {Masaryk University Brno Czech Republic},
title = {Building a web-scale image similarity search system},
journal = {Multimedia Tools and Applications},
publisher = {Springer Netherlands},
issn = {1380-7501},
keyword = {Computer Science},
pages = {599-629},
volume = {47},
issue = {3},
url = {http://dx.doi.org/10.1007/s11042-009-0339-z},
note = {10.1007/s11042-009-0339-z},
year = {2010}
}
Velký tučný článek o MUFINu. Na začátku dobré počítání exploze dat. Článek má dvě hlavní témata - budování CoPhIR kolekce
a vytvoření scalable search system. Porovnání centralized a distributed implementace, použití různých indexů.
Zagoris, Arampatzis, Chatzichristofis: www.MMRetrieval.net: A Multimodal Search Engine. SISAP 2010.
plný text článku,
bibtex
@inproceedings{Zagoris:2010:WMS:1862344.1862363,
author = {Zagoris, Konstantinos and Arampatzis, Avi and Chatzichristofis, Savvas A.},
title = {www.MMRetrieval.net: a multimodal search engine},
booktitle = {Proceedings of the Third International Conference on SImilarity Search and APplications},
series = {SISAP '10},
year = {2010},
isbn = {978-1-4503-0420-7},
location = {Istanbul, Turkey},
pages = {117--118},
numpages = {2},
url = {http://doi.acm.org/10.1145/1862344.1862363},
doi = {http://doi.acm.org/10.1145/1862344.1862363},
acmid = {1862363},
publisher = {ACM},
address = {New York, NY, USA},
}
Dvoustránkový paper o systému, používá distribuované indexy a paralelní vyhledávání (detaily neznámé),
modality kombinuje pomocí late fusion, uživatel si volí způsob kombinace a váhy.
Kludas, Bruno, Marchand-Maillet: Information Fusion in Multimedia Information Retrieval. 2008
plný text článku,
bibtex
@incollection {springerlink:10.1007/978-3-540-79860-6_12,
author = {Kludas, Jana and Bruno, Eric and Marchand-Maillet, Stéphane},
affiliation = {University of Geneva Switzerland},
title = {Information Fusion in Multimedia Information Retrieval},
booktitle = {Adaptive Multimedial Retrieval: Retrieval, User, and Semantics},
series = {Lecture Notes in Computer Science},
editor = {Boujemaa, Nozha and Detyniecki, Marcin and Nürnberger, Andreas},
publisher = {Springer Berlin / Heidelberg},
isbn = {},
pages = {147-159},
volume = {4918},
url = {http://dx.doi.org/10.1007/978-3-540-79860-6_12},
note = {10.1007/978-3-540-79860-6_12},
year = {2008}
}
Hezký přehled přístupů k information fusion, kategorizace, odkazy. V praktické části porovnání několika přístupů
- používají SVM klasifikátory, malé testovací datasety. Kategorizace podle počtu modalit a zdrojů. Multi-modal
fusion může být sériová, paralelní a hierarchická. Jiné dělené - complementary, cooperative a competitive fusion
(podle toho, jestli zdroje informace doplňují, nebo upřesňují výběr). Fusion může probíhat na různých úrovních
- data/feature, classifier/score, decision level. Performance improvement boundaries.
- The JDL working group defined information fusion as "an information process
that associates, correlates and combines data and information from single or
multiple sensors or sources to achieve refined estimates of parameters, characteristics, events and behaviors"
- Drawbacks in data and feature fusion are problems due to
the ’curse of dimensionality’, its computationally expensiveness and that it needs
a lot of training data
- It can be said to be throughout
faster because each modality is processed independently which is leading to a
dimensionality reduction. Decision fusion is however seen as a very rigid solution,
because at this level of processing only limited information is left.
- For information retrieval systems the situation is not as trivial. For
example, three different effects in rank aggregation tasks can be exploited with
fusion [4]:
(1) Skimming effect: the lists include diverse and relevant items
(2) Chorus effect: the lists contain similar and relevant items
(3) Dark Horse effect: unusually accurate result of one source
According to the theory presented in the last section, it is impossible to exploit
all effects within one approach because the required complementary (1) and
cooperative (2) strategy are contradictory.
Zhou, Depeursinge, Muller: Information Fusion for Combining Visual and Textual Image Retrieval. Pattern Recognition 2010
plný text článku,
bibtex
@INPROCEEDINGS{5595739,
author={Xin Zhou and Depeursinge, A. and Muller, H.},
booktitle={Pattern Recognition (ICPR), 2010 20th International Conference on}, title={Information Fusion for Combining Visual and Textual Image Retrieval},
year={2010},
month={aug.},
volume={},
number={},
pages={1590 -1593},
keywords={ImageCLEF medical image retrieval;dark horse effect;information fusion algorithm;logarithmic rank penalization;maximum combination;multi-modality fusion;single modality fusion;stable normalization;textual image retrieval;visual image retrieval;image fusion;image retrieval;},
doi={10.1109/ICPR.2010.393},
ISSN={1051-4651},
}
Zkouší různé metody kombinování výsledků s late fusion strategií, porovnávají vliv na fusion
efekty - chorus, dark horse. maximum combinations, sum combinations, product of maximum and a non-zero number.
Various normalization strategies tried.
Moulin, Largeron, Gery: Impact of Visual Information on Text and Content Based Image Retrieval. 2010
plný text článku,
bibtex
@incollection {springerlink:10.1007/978-3-642-14980-1_15,
author = {Moulin, Christophe and Largeron, Christine and Géry, Mathias},
affiliation = {Université de Lyon, F-42023 Saint-Étienne, France},
title = {Impact of Visual Information on Text and Content Based Image Retrieval},
booktitle = {Structural, Syntactic, and Statistical Pattern Recognition},
series = {Lecture Notes in Computer Science},
editor = {Hancock, Edwin and Wilson, Richard and Windeatt, Terry and Ulusoy, Ilkay and Escolano, Francisco},
publisher = {Springer Berlin / Heidelberg},
isbn = {},
pages = {159-169},
volume = {6218},
url = {http://dx.doi.org/10.1007/978-3-642-14980-1_15},
note = {10.1007/978-3-642-14980-1_15},
year = {2010}
}
Late fusion of visual and text, weighted sum, zkoumají vliv vah. Součást ImageCLEF multimedia.
SIFT, bag of words. Z query objektu i db objektů extrahují text a visual deskriptory,
obojí počítají podle tf-idf.
Clinchant, Ah-Pine, Csurka: Semantic Combination of Textual and Visual Information in Multimedia Retrieval. ICMR 2011
plný text článku,
bibtex
@inproceedings{Clinchant:2011:SCT:1991996.1992040,
author = {Clinchant, St\'{e}phane and Ah-Pine, Julien and Csurka, Gabriela},
title = {Semantic combination of textual and visual information in multimedia retrieval},
booktitle = {Proceedings of the 1st ACM International Conference on Multimedia Retrieval},
series = {ICMR '11},
year = {2011},
isbn = {978-1-4503-0336-1},
location = {Trento, Italy},
pages = {44:1--44:8},
articleno = {44},
numpages = {8},
url = {http://doi.acm.org/10.1145/1991996.1992040},
doi = {http://doi.acm.org/10.1145/1991996.1992040},
acmid = {1992040},
publisher = {ACM},
address = {New York, NY, USA},
keywords = {information fusion, multimedia retrieval},
}
"Image and textual queries are expressed at different semantic levels" - one should not combine them independently
as most information fusion techniques do. Ví se, že samotný text search funguje líp než samotný visual, taky se ví,
že kombinace pomáhá. Takže, jak je zkombinovat co nejlíp - manage the complementarities between image and text search?
Hezky vysvětlují rozdíl mezi early a late fusion. Dále uvádějí transmedia fusion: first use one of the modalities to
gather relevant documents and the swith to the other modality. In many experiments reported in the
literature, it has been shown that either late fusion or transmedia fusion approaches have been
performing better than early fusion techniques. Na druhou stranu, image reranking podle nějakého článku
z ImageCLEF horší než čistě text search. Nebude to tím, že se v ranking ignoruje text distance? Proto oni
navrhují combine image reranking with late fusion, tedy nejprve text searchem vybrat kandidáty,
pak rankovat podle text+visual. Pro předvýběr používají K=1000.
- There is a semantic mismatch between visual and textual
queries: image queries are ambiguous for humans from a
semantic viewpoint. Fusion techniques should be asymmetric since text and image are expressed at different semantic
levels.
- Visual techniques do work and are effective to retrieve visually similar images but they
usually fail in multimedia retrieval due to the semantic mismatch
Park, Nang: Content Based Web Image Retrieval System Using Both MPEG-7 Visual Descriptors and Textual Information. MMM 2007
plný text článku,
bibtex
@incollection {springerlink:10.1007/978-3-540-69423-6_64,
author = {Park, Joohyoun and Nang, Jongho},
affiliation = {Dept. of Computer Science and Engineering, Sogang University, 1, ShinsuDong, MapoGu, Seoul, 121-742 Korea},
title = {Content Based Web Image Retrieval System Using Both MPEG-7 Visual Descriptors and Textual Information},
booktitle = {Advances in Multimedia Modeling},
series = {Lecture Notes in Computer Science},
editor = {Cham, Tat-Jen and Cai, Jianfei and Dorai, Chitra and Rajan, Deepu and Chua, Tat-Seng and Chia, Liang-Tien},
publisher = {Springer Berlin / Heidelberg},
isbn = {},
pages = {659-669},
volume = {4351},
url = {http://dx.doi.org/10.1007/978-3-540-69423-6_64},
note = {10.1007/978-3-540-69423-6_64},
year = {2006}
}
Web search system komplet - stahování obrázků, indexace, hledání. Hledá podle text and visual, early fusion.
Text deskriptory získány ze stránky, potom přefiltrovány pomocí naučených asociací mezi visual concepts
a keywords (propojení pomocí WordNetu). Text&visual index - hierarchical bitmap index.
He, Xiong, Yang, Park: Using Multi-Modal Semantic Association Rules to fuse keywords and visual features automatically for Web image retrieval. Information Fusion 2011
plný text článku,
bibtex
@article{He2011223,
title = "Using Multi-Modal Semantic Association Rules to fuse keywords and visual features automatically for Web image retrieval",
journal = "Information Fusion",
volume = "12",
number = "3",
pages = "223 - 230",
year = "2011",
note = "Special Issue on Information Fusion in Future Generation Communication Environments",
issn = "1566-2535",
doi = "DOI: 10.1016/j.inffus.2010.02.001",
url = "http://www.sciencedirect.com/science/article/pii/S1566253510000230",
author = "Ruhan He and Naixue Xiong and Laurence T. Yang and Jong Hyuk Park",
keywords = "Web image retrieval",
keywords = "Multi-Modal Semantic Association Rule (MMSAR)",
keywords = "Association rule mining",
keywords = "Inverted file",
keywords = "Relevance Feedback (RF)"
}
Vyvíjejí VAST web image retrieval system. Hledají asociace mezi visual features a text.
Information fusion dělí na automatic a non-automatic, v automatic tyto kategorie: pseudo-relevance feedback,
online clustering, long-term RF learning. Odkazují nějaké analýzy chování uživatele - lazy user.
Jejich technologie - automatically fuse image and text using Multi-Modal Semantic Association Rule
- dává dohromady single keyword a několik visual features. Dost detailní popis tvorby asociací.
Pomocí získaných asociací se přerankují výsledky prvotního text-based vyhledávání.
Depeursinge, Müller: Fusion Techniques for Combining Textual and Visual Information Retrieval. Chapter 6 of ImageCLEF Experimental Evaluation in Visual Information Retrieval, Springer 2010
plný text článku,
bibtex
@incollection {springerlink:10.1007/978-3-642-15181-1_6,
author = {Depeursinge, Adrien and Müller, Henning},
affiliation = {University and University Hospitals of Geneva (HUG), Rue Gabrielle–Perret–Gentil 4, 1211 Geneva 14, Switzerland},
title = {Fusion Techniques for Combining Textual and Visual Information Retrieval},
booktitle = {ImageCLEF},
series = {The Kluwer International Series on Information Retrieval},
editor = {Croft, W. Bruce and Müller, Henning and Clough, Paul and Deselaers, Thomas and Caputo, Barbara},
publisher = {Springer Berlin Heidelberg},
isbn = {978-3-642-15181-1},
keyword = {Computer Science},
pages = {95-114},
volume = {32},
url = {http://dx.doi.org/10.1007/978-3-642-15181-1_6},
note = {10.1007/978-3-642-15181-1_6},
year = {2010}
}
Kategorizace přístupů k data fusion z článků na ImageCLEF za posledních 7 let. Identifikují tři základní přístupy
- inter-media query expansion, early fusion, late fusion (by far the most widely used). V early fusion uvažují
jednoduše concatenation, jako problém uvádějí curse of dimensionality. V late fusion se rozlišuje rank-based fusion a
score-based fusion, druhá varianta častější, vyžaduje normalizaci. Jedna možná implementace late fusion je intersection - uvedeno
několik variant, jak zadefinovat. Jiná varianta - reordering; odkazy na publikace o text search + visual reordering a naopak.
Detailně se popisuje několik metod kombinování - SUM a spol. Dále popisují text a visual query expansion.
Arampatzis, Zagoris, Chatzichristofis: Fusion vs. Two-Stage for Multimodal Retrieval. ECIR 2011
plný text článku,
bibtex
@incollection {springerlink:10.1007/978-3-642-20161-5_88,
author = {Arampatzis, Avi and Zagoris, Konstantinos and Chatzichristofis, Savvas},
affiliation = {Department of Electrical and Computer Engineering, Democritus University of Thrace, Xanthi, 67100 Greece},
title = {Fusion vs. Two-Stage for Multimodal Retrieval},
booktitle = {Advances in Information Retrieval},
series = {Lecture Notes in Computer Science},
editor = {Clough, Paul and Foley, Colum and Gurrin, Cathal and Jones, Gareth and Kraaij, Wessel and Lee, Hyowon and Mudoch, Vanessa},
publisher = {Springer Berlin / Heidelberg},
isbn = {},
pages = {759-762},
volume = {6611},
url = {http://dx.doi.org/10.1007/978-3-642-20161-5_88},
note = {10.1007/978-3-642-20161-5_88},
year = {2011}
}
Porovnávají late fusion text a visual search results s visual reordering z hlediska kvality, vyjde jim to celkem stejně.
Čas neměřili, ale v diskuzi uvádějí, že rankování je rychlejší, tudíž lepší. Porovnávali to na zhruba 200 000 objektech
z Wikipedie.
Kokar, Tomasik, Weyman: Formalizing classes of information fusion systems. Information Fusion 2004
plný text článku,
bibtex
@article{DBLP:journals/inffus/KokarTW04,
author = {Mieczyslaw M. Kokar and
Jerzy A. Tomasik and
Jerzy Weyman},
title = {Formalizing classes of information fusion systems},
journal = {Information Fusion},
volume = {5},
number = {3},
year = {2004},
pages = {189-202},
ee = {http://dx.doi.org/10.1016/j.inffus.2003.11.001},
bibsource = {DBLP, http://dblp.uni-trier.de}
}
Snaha o formální uchopení information fusion. Věnují se early a late fusion, ukazují, že decision fusion je
podtřídou data fusion. Formalismus zajímavý, používají pěkná schémata, asi by stálo za to někdy na to víc kouknout.
Fagin: Combining Fuzzy Information: an Overview. SIGMOD 2002
plný text článku,
bibtex
@article{Fagin:2002:CFI:565117.565143,
author = {Fagin, Ronald},
title = {Combining fuzzy information: an overview},
journal = {SIGMOD Rec.},
volume = {31},
issue = {2},
month = {June},
year = {2002},
issn = {0163-5808},
pages = {109--118},
numpages = {10},
url = {http://doi.acm.org/10.1145/565117.565143},
doi = {http://doi.acm.org/10.1145/565117.565143},
acmid = {565143},
publisher = {ACM},
address = {New York, NY, USA},
}
Naive algorithm, Fagin algorithm a Threshold algorithm pro vyhodnocování kombinovaných
dotazů nad systémem, který umí vracet uspořádané seznamy podle jednotlivých deskriptorů (dva druhy přístupu
k datům - sorted a random access, random dražší). Dokáže se,
že Threshol algorithm je optimální přesný algoritmus pro tento problém. Dále se diskutuje aproximativní
algoritmus, který skončí předčasně, když je dosaženo dané míry přesnosti.
- There is an obvious naive algorithm for obtaining the top k answers. Under sorted access, it looks at
every entry in each of the m sorted lists, computes (using t) the overall grade of every object, and returns
the top k answers. The naive algorithm has linear middleware cost (linear in the database size), and
thus is not efficient for a large database.
- Fagin algorithm:
- Do sorted access in parallel to each of the m sorted lists Li. (By “in parallel”, we mean that we
access the top member of each of the lists under sorted access, then we access the second member
of each of the lists, and so on.) Wait until there are at least k “matches”, that is, wait until there
is a set H of at least k objects such that each of these objects has been seen in each of the m lists.
- For each object R that has been seen, do random access as needed to each of the lists Li to find
the ith field xi of R.
- Compute the grade t(R) = t(x1, . . . , xm) for each object R that has been seen. Let Y be a set
containing the k objects that have been seen with the highest grades (ties are broken arbitrarily).
The output is then the graded set {(R, t(R)) |R ∈ Y }.
- Threshold algorithm:
- Do sorted access in parallel to each of the m sorted lists Li. As an object R is seen under sorted
access in some list, do random access to the other lists to find the grade xi of object R in every
list Li. Then compute the grade t(R) = t(x1, . . . , xm) of object R. If this grade is one of the k
highest we have seen, then remember object R and its grade t(R) (ties are broken arbitrarily, so
that only k objects and their grades need to be remembered at any time).
- For each list Li, let xi be the grade of the last object seen under sorted access. Define the threshold
value τ to be t(x1, . . . , xm). As soon as at least k objects have been seen whose grade is at least
equal to τ, then halt.
- Let Y be a set containing the k objects that have been seen with the highest grades. The output
is then the graded set {(R, t(R)) |R ∈ Y }.
- Aggregation function: FA and TA are correct for monotone aggregation functions t
(that is, the algorithm successfully finds the top k answers). An aggregation function t is strict
if t(x1, . . . , xm) = 1 holds precisely when xi = 1 for
every i. Thus, an aggregation function is strict if it takes on the maximal value of 1 precisely when each
argument takes on this maximal value. We would certainly expect an aggregation function representing
the conjunction to be strict. In fact, it is reasonable to think of strictness
as being a key characterizing feature of the conjunction.
Fagin: Combining Fuzzy Information from Multiple Systems. 1999
(plný text článku)
Jak kombinovat víc deskriptorů. Definují se potřebné vlastnosti agregační funkce,
navržen Fagin algorithm.
- Let us define an m-ary scoring function to be a function from [0, l]m to [0, 1]. For the sake of
generality, we will consider m-ary scoring functions for evaluating conjunctions of m atomic queries, although
in practice an m-ary conjunction is almost always evaluated by using an associative 2-ary function that
is iterated. Analogously to the binary case, we say that an m-ary scoring function t is monotone if
t(xl, ..., xm)≤t(x1', ..., xm') when xi ≤ xi' for every i. As discussed before, monotonicity is a reasonable
property to expect a scoring function to obey. Another such property is strictness: an m-ary scoring function t
is strict if t(xl, ..., xm) = 1 iff xi = 1 for every i. Thus, a scoring function is strict if it takes on the
maximal value of 1 precisely if each argument takes on this maximal value. Scoring functions considered
in the literature seem to be monotone and strict. In particular, scoring functions derived from “triangular
norms” are monotone and strict. Another important class of scoring functions include various
weighted and unweighed arithmetic and geometric means, which Thole, Zimmerman, and Zysno found to
perform empirically quite well. These are also monotone and strict.
Tung, Zhang, Koudas, Ooi: Similarity Search: A Matching Based Approach. VLDB 06.
(plný text článku)
Kombinované dotazy: zatímco obvykle se podobnost objektů určuje na základě kombinace fixní sady deskriptorů, článek navrhuje používat proměnlivou podmnožinu deskriptorů, a to ty, které jsou nejpodobnější (důvod - hlavně u vyšších dimenzí velká šance, že některý deskriptor "ustřelí", i když je objekt jinak velmi dobrý).
-
NN problem: distance between query object Q and data object over a FIXED set of features. Problems of this
approach - partial similarities undiscovered, distance affected by a few dimensions with high dissimilarity
(this phenomenon more obvious for high-dimensional data; in real applications - bad pixels, noise in signal, ...)
-
Model: object = multidimensional point; attributes sorted in each dimension,
cost is measured by the number of attributes retrieved; attributes sorted
with respect to their values, not distances to Q!
-
k-n-match problem: matching between Q and data objects in n dimensions, n < dimensionality d; these n dimensions
are determined dynamically to make Q and data objects returned match best
Definition: N-match difference: Given two d-dimensional points P (p1, p2, ..., pd) and
Q (q1, q2, ..., qd), let δi = |pi - qi|, i = 1, ..., d. Sort the array
δ1, ..., δd in increasing order and let the sorted array be
δ1' ,..., δd'. Then δn' is the n-match difference of point P
with regard to Q.
N-match difference is not a metric!
Definition: The n-match problem: Given a d-dimensional database DB, a query point Q and
an integer n (1 ≤ n ≤ d), find the point P ∈ DB that has
the smallest n-match difference with regard to Q. P is called
the n-match point of Q.
Definition: The k-n-match problem: Given a d-dimensional database DB of cardinality c, a query
point Q, an integer n (1 ≤ n ≤ d), and an integer k ≤ c,
find a set S which consists of k points from DB so that for
any point P1 ∈ S and any point P2 ∈ DB - S, the n-match
difference between P1 and Q is less than or equal to the n-
match difference between P2 and Q. The S is the k-n-match
set of Q.
-
frequent k-n-match: finds a set of objects that appears in the k-n-match answers
most frequently for a range of values of n
The frequent k-n-match problem:
Given a d-dimensional database DB of cardinality c, a query
point Q, an integer k ≤ c, and an integer range [n0; n1]
within [1; d], let S0, ..., Si be the answer sets of k-n0-match,
..., k-n1-match, respectively. Find a set T of k points, so
that for any point P1 ∈ T and any point P2 ∈ DB - T, P1’s
number of appearances in S0, ..., Si is larger than or equal
to P2’s number of appearances in S0, ..., Si.
- Algorithm for (frequent) k-n-match problem: FA doesn't work
as the aggregation function used in k-n-match is not monotone.
AD algorithm for k-n-match Search: We first locate each dimension of the query Q in
the d sorted lists. Then we retrieve the individual attributes
in ascending order of their differences to the corresponding
attributes of Q. When a point ID is first seen n times, this
point is the first n-match. We keep retrieving the attributes
until k point ID’s have been seen at least n times. Then we
can stop. We call this strategy of accessing the attributes
in Ascending order of their Differences to the query point’s
attributes as the AD algorithm.
- Effectivity evaluation:
- To validate the statement that the traditional kNN query
leaves many partial similarities uncovered, we first use a
image database to visually show this fact.
- In order to evaluate effctiveness from a (statistically) quantitative view, we use the class stripping technique, which is described as follows. We use five real data sets with dimensionalities varying from 4 to 34 ... Each record has an additional variable indicating which class it belongs to. By the class stripping technique, we strip this class tag from each point and use different techniques to find the similar objects to the query objects. If the answer and the query belong to the same class, then the answer is correct. The more correct ones in the returned answers, statistically, the better the quality of the similarity searching method.
Nápady: mohlo by se použít pro přerankování výsledků Combined Query, ale problémy:
ignoruje se agregační funkce - pro sumu to asi jde vyřešit normováním jednotlivých sčítanců?
Manning, Raghavan, Schutze: Introduction to Information Retrieval. Cambridge University Press. 2008.
HTML version,
bibtex
@book{IRbook08,
author = {Christopher D. Manning and
Prabhakar Raghavan and
Hinrich Sch{\"u}tze},
title = {Introduction to information retrieval},
publisher = {Cambridge University Press},
year = {2008},
isbn = {978-0-521-86571-5},
pages = {I-XXI, 1-482},
bibsource = {DBLP, http://dblp.uni-trier.de}
}
Obsahuje dobrou kapitolu o evaluačních metodách - co je vhodné pro rankované výsledky,
neúplnou ground truth.
Järvelin, Kekäläinen: Cumulated gain-based evaluation of IR techniques. ACM Trans. Inf. Syst., 2002
plný text článku,
bibtex
@article{DBLP:journals/tois/JarvelinK02,
author = {Kalervo J{\"a}rvelin and
Jaana Kek{\"a}l{\"a}inen},
title = {Cumulated gain-based evaluation of IR techniques},
journal = {ACM Trans. Inf. Syst.},
volume = {20},
number = {4},
year = {2002},
pages = {422-446},
ee = {http://doi.acm.org/10.1145/582415.582418},
bibsource = {DBLP, http://dblp.uni-trier.de}
}
Popisuje metrik Cumulated Gain, Discounted Cumulated Gain, Normalized DCG. Vhodné pro rankované
výsledky, poradí si i s neúplnou GT.
Nowak, Lukashevich, Dunker, Rueger: Performance Measures for Multilabel Evaluation. MIR 2010
plný text článku
Popis a porovnání různých performance measures - Precision, Recall, Mean
Average Precision a další. Concept-based comparison, example-based, hierarchical, ontology-based.
Srovnávají to na datech z ImageCLEF, doporučení co používat (používá se teď pro ImageCLEF) - MAP,
F-measure.
Fagin, Kumar, Sivakumar: Comparing Top k Lists. 2003
(plný text článku)
Rozebírá standardní možnosti porovnávání uspořádaných seznamů, navrhuje nové pro
potřeby porovnávání top-k výsledků (tady se musí uvažovat, že neznáme uspořádání celé domény). Hodně teoreticky
rozebrané, řazení měřicích funkcí do tříd, zkoumání metrických vlastností.
- There are several standard methods for comparing two permutations, such as Kendall’s tau
and Spearman’s footrule. We cannot simply apply these known methods, since they deal only with
comparing one permutation against another over the same elements.
- A fairly straightforward attempt at defining a distance measure is to compute the intersection
of the two top k lists (viewing them as sets). In order to obtain a metric, we consider the notion
of the symmetric difference (union minus the intersection), appropriately scaled. This,
unfortunately, is not adequate for the top k distance problem,since two top 10 lists that
are reverses of each other would be declared to be “very close.” We propose natural extensions
of this idea that leads to a metric for top k lists. Briefly, the idea is to truncate the top
k lists at various points i ≤ k,compute the symmetric diffference metric between the resulting
top i lists, and take a suitable combination of them.
- Kendall’s tau metric between permutations is defined as follows. For each pair {i, j} of
distinct members of D, if i and j are in the same order in σ1 and σ2, then let
Ki,j(σ1,σ2)=0; if i and j are in the opposite order, then let Ki,j(σ1,σ2) = 1.
Kendall’s tau is given by sum of Ki,j (σ1,σ2). The maximum value of
K(σ1,σ2) is n(n-1)/2, which occurs when σ1 is the reverse of σ2
(that is, when σ1(i)+ σ2(i)= n + 1 for each i).
- Spearman’s footrule metric is the L1 distance between two permutations. Formally, it is
defined by F(σ1,σ2)= Sum |σ1(i) - σ2(i)|. The maximum value of
F(σ1,σ2) is n2/2 when n is even,and (n + 1)(n - 1)/2 when n is odd.
Again, the maximum occurs when σ1 is the reverse of σ2.
- Spearman’s rho is the L2 distance between two permutations. Formally,
ρ(σ1,σ2) = (Sum |σ1(i) - σ2(i)|2)1/2
and it can be shown that ρ(·, ·) is a metric. The maximum value of ρ(σ1,σ2) is
(n(n+1)(2n+1)/3)1/2, which occurs when σ1 is the reverse of σ2.
- Let p be a fixed parameter with 0 ≤ p ≤ 1 (penalty). We define the Kendall distance with
penalty parameter p as follows:
- Case 1 (i and j appear in both top k lists): If i and j are in the same order then let
K(p)i,j (τ1,τ2) = 0. If i and j are in the opposite order (such as i being ahead of j in τ1
and j being ahead of i in τ2), then let the penalty K(p) i,j (τ1,τ2)=1.
-
- Case 2 (i and j both appear in one top k list (say τ1), and exactly one of i or j,
say i, appears in the other top k list (τ2)): If i is ahead of j in τ1,then let the penalty
K(p)i,j (τ1,τ2) = 0, and otherwise let K(p)i,j (τ1,τ2) = 1. Intuitively,we know that i is
ahead of j as far as τ2 is concerned, since i appears in τ2 but j does not.
- Case 3 (i, but not j, appears in one top k list (say τ1), and j, but not i, appears in
the other top k list (τ2)): Then let the penalty K(p) i,j (τ1,τ2) = 1. Intuitively, we
know that i is ahead of j as far as τ1 is concerned and j is ahead of i as far as τ2 is concerned.
- Case 4 (i and j both appear in one top k list (say τ1), but neither i nor j appears
in the other top k list (τ2)): This is the interesting case (the only case where there is
really an option as to what the penalty should be). In this case, we let the penalty K(p)
i,j (τ1,τ2)= p.
- Let l be a real number greater than k. The footrule distance with location parameter l,
denoted F(l), is obtained by placing all missing elements in each
of the lists at position l and computing the usual footrule distance between them.
A natural choice for l is k + 1. Another possibility is l = (3k -z +1)/2
which forms a "dynamic" version of F(l), where l = (3k - z +1)/2 actually depends on τ1 and τ2.
Note that l =(3k - z +1)/2 is the average of k + 1 and 2k - z, where
the latter number is the size of D = Dτ1 ∪ Dτ2. Taking l = (3k - z +1)/2
corresponds intuitively to “placing the missing elements at an average location”.
- It is convenient to deal with normalized versions of distance measures by dividing
each measure by its maximum value. The normalized version is then a distance measure that lies in the interval [0, 1].
- Algorithmic application: Given r ranked lists τ1,...,τr
(either full lists or top k lists) of “candidates,” the rank aggregation problem with respect
to a distance measure d is to compute a list τ (again, either a full list or
another top k list) such that the difference between the new and original lists is minimized.
It is argued that Kendall’s tau and its variants are good measures to use, both in the
context of full lists and top k lists. Unfortunately, computing an optimal aggregation of
several full or top k lists is NP-hard for each of the Kendall measures. In this context, our
notion of an equivalence class of distance measures comes in handy.
Bustos, Skopal: Dynamic Similarity Search in MultiMetric Spaces. MIR 2006.
(plný text článku)
Článek popisuje strukturu M3-tree, která má umožňovat dotazy
nad více metrikami s dynamickým určováním koeficientů do váženého součtu subdistancí.
Vychází se z toho, že koeficienty jsou z intervalu [0,1] a tudíž existuje horní
mez součtu. Strom ukládá parciální vzdálenosti a dynamicky odhaduje horní mez pro covering radius uzlu.
Dynamické koeficienty se určují na základě podobnosti objektu k malé množině předem klasifikovaných objektů.
Článek je zaměřen na rychlost výpočtu, nikoli kvalitu výsledků.
- Usually, a single metric function is used to compute the similarity between two objects in the metric space.
However, a recent trend to improve the effectiveness of the similarity search resorts to use several metric functions. The
(dis)similarity function is computed as a linear combination of some selected metrics. It follows (from metric spaces
theory) that the combined distance function is also a metric.
Definition 1. (linear multi-metric): Let M = <δ_i> be a vector of metric functions, and let W = <w_i>
be a vector of weights, with |M| = |W| = m and ∀i w_i ∈ [0, 1].
The linear multi-metric (or linear combined metric function) is defined as
D_W(O1,O2) = ∑i=1 to m w_i · δ_i(O1,O2).
- The problem with a static combination of metrics (i.e., where the weights of the linear combination are fixed) is that
usually not all metrics are well-suited for performing similarity search with all query objects. Moreover, a bad-suited
metric may “spoil” the final result of the query. Thus, to further improve the effectiveness of the search system, methods
for dynamic combinations of metrics have been proposed, where the query processor weighs the contribution of each
metric depending on the query object (i.e., big weights are assigned to the “good” metrics for that query object, and
low weights are assigned to the “bad metrics”, according to some quality criteria). This means that, instead of a single
metric, the system uses a dynamic metric function (multimetric), where a different metric is computed to perform
each similarity query.
- We implemented a query processor based on the entropy impurity method to compute the dynamic weights for
each 3D feature vector. This method uses a reference dataset that is classified in object classes (in our case, we used the
classified subset of the 3D models database). For each feature vector, a similarity query is performed on the reference
dataset. Then, the entropy impurity is computed looking at the model classes of the first t retrieved objects: It is equal
to zero if all the first t retrieved objects belong to the same model class, and it has a maximum value if each of the t
object belongs to a different model class.
Bustos, Keim, Saupe, Schreck, Vranic: Using Entropy Impurity for Improved 3D Object Similarity Search.
ICME 2004
(plný text článku)
Snaží se zefektivnit vyhledávání v 3D objektech. Využívá se několik deskriptorů,
pro každý query objekt se zjistí, které jsou pro něj nejdůležitější, a to pomocí entropy impurity measure.
Při pokusech se používá trénovací množina, v níž jsou objekty předem klasifikovány do kategorií. Kategorie jsou dány předem, pro každou z nich známe několik reprezentantů (trénovací objekty). Pro daný query objekt a deskriptor seřadíme objekty z trénovací množiny podle vzdálenosti dané tímto deskriptorem. Čím více objektů, které jsou na prvních místech, patří do stejné kategorie, tím vhodnější je tento deskriptor pro popis daného query objektu. Zajímavý pro distinct kNN na tom může být princip Entropy Impurity measure – pokud všechny blízké objekty ze stejné kategorie, EI=0, naopak pokud blízké objekty rovnoměrně ze všech kategorií, EI=1.
- As we learned from our experiments, the effectiveness of a given
FV (feature vector) cannot be assessed for the general case, as it depends on the specific type of 3D object that one wants to search.
For example, we have observed that the best effectiveness for “car models” is achieved using the depth buffer FV, but the
best effectiveness for “sea animal models” is achieved using the silhouette FV. In this work, we attempt to improve the
effectiveness of a similarity search system for a general 3D object database, where no restrictions are imposed on the 3D
models, as they are allowed to represent any type of object.
- We introduce a heuristic for the a priori estimation of individual FV performance. We then define two methods that
use this estimator to improve the effectiveness of the retrieval system: The first one makes use of the heuristic to select a
good FV given a query object from the pool of available FVs. The other one uses it to combine FVs with weights based
on the estimator value.
- We use an estimator based on the entropy impurity for determining the best FVs to use. The entropy impurity is a well
known measure used in the context of decision tree induction, where it measures the “impurity” of a node N of the tree
w.r.t. the elements assigned to N. If these elements all have the same class label, then the impurity is 0, otherwise it is a
positive value that increases up to a maximum when all classes are equally represented.
- An open problem is the automatic selection of a FV or combination of FVs for searching for a given query object in
a database consisting entirely of unclassified objects. In this case, the proposed methods cannot be directly applied.
Bustos, Keim, Saupe, Schreck, Vranic: Automatic Selection and Combination of Descriptors
for Effective 3D Similarity Search. ISMSE 04
(plný text článku)
Další článek na stejné téma jako předchozí. Pomocí trénovací sady objektů, které jsou
rozčleněny do kategorií, se zjistí, které deskriptory jsou pro daný objekt podstatné. Pak se hledá podle
nejdůležitějšího deskriptoru nebo lépe podle lineární kombinace, kde váhy jsou určeny na základě
důležitosti deskriptoru pro daný objekt.
Amato, Falchi, Gennaro, Rabitti, Savino, Stanchev:: Improving Image Similarity Search Effectiveness
in a Multimedia Content Management System. MIS 2004
(plný text článku)
Autoři pro danou kolekci obrázků a množinu šesti MPEG-7 deskriptorů zkoumají, jaké
váhy přiřadit deskriptorům, aby se získal co nejlepší výsledek. Váhy mají být univerzální pro celou
kolekci. Zkoumají to tak, že dělají experimenty s uživateli, kteří označují nejlepší výsledky
(číselně, od 0 do 1), pak porovnávají, pro které deskriptory to počítač seřadil podobně
a pro které ne. Podle míry podobnosti se pak odvodí koeficienty agregační funkce.
Falchi, Lucchese, Perego, Rabitti: CoPhIR: COntent-based Photo Image Retrieval. 2008.
(plný text článku)
Popisuje, proč a jak byla vytvářena kolekce CoPhIR (výběr zdroje, výběr sbíraných metadat, způsob
crawlování a indexování - velmi náročné, používají se gridy).
Skala: Measuring the Diffculty of Distance-Based Indexing. SPIRE 2005.
(plný text článku)
Počítá se intrinsic dimensionality daného metrického prostoru a zvolené
distanční funkce. Tato veličina se určuje ze střední hodnoty a rozptylu rozložení vzdáleností pro množinu náhodných
dvojic objektů a měla by umožnit porovnávat, jak náročné je indexování daného prostoru
ve srovnání s n-dimenzionálním vektorovým prostorem. Podle hodnoty intrinsic dimensionality se dá rozhodnout,
která distanční funkce je vhodnější pro indexování daného prostoru.
K intrinsic dimensionality viz také Chavez, Navarro: Measuring the dimensionality of general metric spaces.
V článku se na základě této veličiny provádí výpočty pro několik zvolených množin objektů a několik variant
distančních funkcí. Vyhodnocuje se dimenzionalita a nejvhodnější funkce.
Hodně teoretické, důkazy, pravděpodobnosti.
Chavez, Navarro: Measuring the dimensionality of general metric spaces.
Technical Report TR/DCC-00-1, 2000.
(plný text článku)
Složitost vyhledávání závisí na dimenzionalitě prohledávaného prostoru.
Autoři zdůvodňují, že z pohledu vyhledávání je dimensionalita u vektorového prostoru často
jiná než skutečný počet dimenzí. Vyhledávací dimensionalita by měla také být měřitelná
u obecných metrických prostorů, které běžné dimenze nemají. Autoři proto definují tzv.
intrinsic dimensionality, která se počítá ze statistických vlastností histogramu vzdáleností.
Autoři dále ukazují, že známe-li intrinsic dimensionality, můžeme určit meze pro složitost
vyhledávání.
Velkou výhodou navržené míry pro intrinsic dimension (existují i jiné) je její jednoduchost
a levné spočítání pro libovolný metrický prostor.
- The search problem is known to be difficult as the dimension l grows. However, in practice the "intrinsic"
dimension of a real-world vector space is less than l because the elements are not uniformly distributed.
The behavior of all search algorithms is known to be related to the intrinsic dimention, but defining
it is difficult.
- Despite the absence of coordinates in general metric spaces, many authors speak in terms of
"intrinsic dimensionality" of metric spaces as a measure of the difficulty of searching
in them. Several authors have pointed out at the histogram of distances as a tool to measure
the dimensionality, noting that in vecotr spaces the histogram of distances shrinks and
shifts to the right as l grows.
- We introduce a new definition of intrinsic dimensionality that is simple and efficient to estimate
and which is shown analytically and experimentally to capture the essential feature of metric spaces that
determine the behavior of all the search algoritms. We prove analytically that our definition extends naturally
that of vector spaces and that lower bounds on the behavior of a large class of proximity search algorithms
can be stated as a function of our intrinsic dimensionality measure.
- We define the intrinsic dimensionality of a set of points in a metric space in terms
of statistical properties of the histogram of distances. The idea is that, as the space has
higher intrinsic dimension, the mean of the histogram grows and/or its variance is reduced
(at least this is the case onrandom vector spaces).
- Intuitive expanation of the concept: if we consides a random query q and an indexing scheme
based on random pivots, then the possible distances between q and a pivot p are distributed according
to the histogram of the figure. The elimination rule says that we can discard any point u such
that d(p,u) ∉ [d(p,q), d(p,q)+r]. The grayed areas in the figure show the points that
cannot be discarded. As the histogram is more and more concentrated around its mean, less and less
points can be discarded using the information given by d(p,q). Moreover, in many cases the
search radius r must grow as the mean distance grows, which makes the problem even harder.
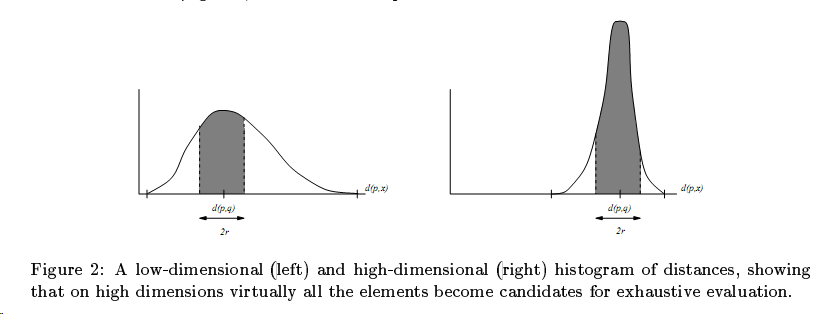
- Definition (intrinsic dimensionality): The intrinsic dimensionality of a metric space
is defined as ρ = µ2 / (2.σ2), where µ and σ2
are the mean and variance of its histogram of distances.
Skala: Counting Distance Permutations. SISAP 2008.
(plný text článku), (rozšířený text článku)
Pro indexování metrických dat existují různé přístupy, které se liší v tom, kolik
a jakých údajů (vzdáleností) je uloženo v indexu. Zde se uvažuje index, který pro každý
datový objekt má uložený seznam k referenčních bodů uspořádaných podle vzdálenosti k danému objektu.
Diskutuje se, že takovýchto seznamů, tj. permutací referenčních bodů, může být podstatně
méně než k!, což má vliv na velikost indexu a rychlost prohledávání.
Indyk, Motwani: Approximate Nearest Neighbors: Towards Removing the Curse of Dimensionality. Proceedings of
the Symposium on Theory of Computing, 1998.
(plný text článku)
Základní článek o LSH, které je prezentováno jako jedna z metod pro řešení
problému PLEB, o kterém se ukazuje, že je "ekvivalentní" (oboustranně redukovatelný na/z) problému NNSearch.
Rozebrány jsou především principy a složitost.
- Overview of existing approaches to NN queries (structures, time complexity)
- Reducing approximate NNS to a new problem - point location in equal balls. Two solutions to the point location problem. One is based on a method akin to the Elias bucketing algorihm - we decompose each ball into a bounded number of cells and store them in a dictionary. This allows us to achieve O(d) query time, while the preprocessing is exponential in d. For the second solution, we introduce the technique of locality-sensitive hashing. The key idea is to use hash functions such that the probability of collision is much higher for objects that are close to each other than for those that are far apart. We prove that existence of such functions for any domain (not necessarily a metric space) implies the existence of fast approximate e-NNS algorithms for that domain, with preprocessing cost only linear in d and sublinear in n (for e > 1).
- Definition: Point Location in Equal Balls (PLEB):
Given n radius-r balls centered at C = (cl, ..., cn) in M = (X,d), devise a data structure which for any query point q ∈ X does the following: if there exists ci ∈ C such that q ∈ B(ci, r) then return ci, else return NO.
Observe that PLEB (e-PLEB) can be reduced to NNS (e-NNS), with the same preprocessing and query costs, as follows: it suffices to find an exact (e-approximate) nearest neighbor and then compare its distance from q with r. There is a reduction in reverse from e-NNS to e-PLEB, with only a small overhead
in preprocessing and query costs. This reduction relies on a data structure called a ring-cover tree.
- We introduce the notion of locality-sensitive hashing and apply it to sublinear-time similarity searching. The definition makes no assumptions about the object similarity measure. In fact, it is applicable to both similarity and dissimilarity measures.
- Definition: Locality-sensitive hashing: A family H = {h:S → U} is called (R,cR, P1, P2)-sensitive if for any q,p,p' ∈ S
- if p ∈ B(q, r1) then PrH[h(q) = h(p)] ≥ P1
- if p' ∉ B(q, r2) then PrH[h(q) = h(p')] ≤ P2.
In order for a locality-sensitive family to be useful, it has to satisfy inequalities p1 > p2 and rl < r2 when D is a dissimilarity measure, or p1 > p2 and r1 > r2 when D is a similarity measure.
- LSH Algorithm for PLEB: For k specified later, define a function family G = (g :
S → Uk} such that g(p) = (h1(p), ..., hk(p)), where hi ∈ H.
The algorithm is as follows. For an integer l we choose l
functions g1 , ... ,gl from G independently and uniformly at
random. During preprocessing, we store each p ∈ P in the
bucket gj(p), for j = 1,..., l. Since the total number of
buckets may be large, we retain only the non-empty buckets
by resorting to hashing. If any bucket contains more
than one element, we retain an arbitrary one. To process a
query q, we search all buckets g1(p) ,..., gl(p). Let p1 ,..., pt
be the points encountered therein. For each pi, if p ∈
B(q, r2) then we return YES and pj, else we return NO.
Let Wb(q) = P- B(q, a), and p* be the point in P closest
to q. The parameters k and I are chosen so as to ensure
that with a constant probability there exists gj such that
the following properties hold:
- gj(p') ≠ gj(q) for all p' ∈ Wr2(q), and
- if p* ∈ B(q, r1) then gj(p*) = gj(q).
- Theorem: Suppose there is a (rl, r2, pl, p2)-sensitive family H for D. Then there exists an algorithm for (rl,r2)-PLEB under measure D which uses O(dn+n1+ρ) space and O(n1ρ) evaluations of the hash function for each query, where ρ = - ln p1 / ln (p1/p2)
Andoni, Indyk: Near-Optimal Hashing Algorithms for Approximate Nearest Neighbor in High Dimensions. COMMUNICATIONS OF THE ACM January 2008/Vol. 51, No. 1.
(plný text článku, prezentace)
Přehledné zopakování principů a definic LSH (k-NN, curse of dimensionality, approximate k-NN, probabilistic approach). Algoritmus - kombinace několika LSH rodin, buď rovnou při hashování, nebo použití více hashovacích tabulek - experimentální porovnání různých nastavení. Několik základních funkcí - pro Hamming distance, l1, l2, vektory, množiny. Nová funkce pro Euklidovskou vzdálenost - mapování do vícedimenzionálního prostoru.
- Problem definition (Randomized R-near neighbor reporting): Given a set P of points in a d-dimensional space Rd, and parameters R > 0, δ >0, construct a data structure that, given any query point q, reports each R-near neighbor of q in P with probability 1 – δ.
- Locality-sensitive hashing: A family His called (R,
cR, P1, P2)-sensitive if for any two points p, q ∈ Rd
- if |p – q| ≤ R then PrH [h(q)= h(p)] ≥ P1,
- if |p – q| ≤ cR then PrH [h(q)= h(p)] ≤ P2.
In order for a locality-sensitive hash (LSH) family to be useful, it has
to satisfy P1 > P2.
- Algorithm: One typically cannot use
H as is since the gap between the probabilities P1 and P2 could be
quite small. Instead, an amplification process is needed in order to
achieve the desired probabilities of collision. Given a family H of hash functions with parameters (R, cR, P1, P2), we amplify the gap between the high probability P1 and low probability P2 by concatenating several functions. In particular, for parameters k and L (specified later), we choose L functions
gj(q)=(h1,j(q),…,hk,j(q)), where ht,j
(1 ≤ t ≤ k, 1 ≤ j ≤ L) are chosen independently and uniformly at random from H. These are the actual functions that we use to hash the data points. The data structure is constructed by placing each point p from the
input set into a bucket gj (p), for j = 1,…,L. Since the total number of
buckets may be large, we retain only the nonempty buckets. In this way, the data
structure uses only O(nL) memory cells; note that it suffices that the
buckets store the pointers to data points, not the points themselves.
To process a query q, we scan through the buckets g1(q),…, gL(q), and
retrieve the points stored in them.
How should the parameter k be chosen? Intuitively, larger values of
k lead to a larger gap between the probabilities of collision for close
points and far points. The benefit of this amplification is that the
hash functions are more selective. At the same time, if k is large then
P1 is small, which means that L must be sufficiently large to ensure
that an R-near neighbor collides with the query point at least once.
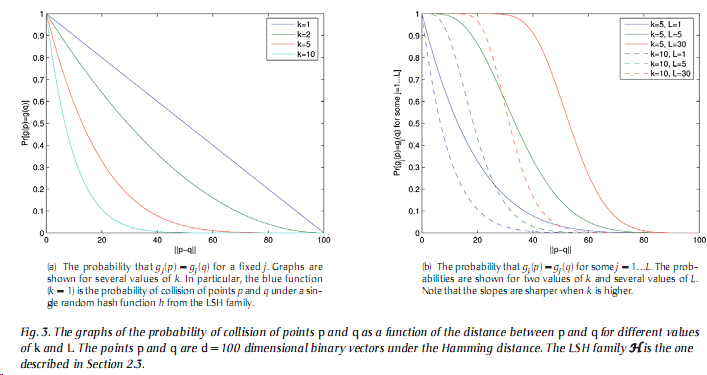
- Near-Optimal LSH Functions for Euclidean Distance: The starting point of our construction is the line partitioning method, where point p was mapped into R1 using a random projection and this line was partitioned into intervals of length w, where w is a parameter.
We define a “multi-dimensional version” of this approach. Specifically, we first perform random projection into Rt, where t is super-constant, but relatively small (i.e., t = o(log n)). Then we partition the space Rt
into cells. The hash function function returns the index of the cell which contains projected point p. Ball partitioning is used on Rt: We create a sequence of balls B1, B2…, each of radius w, with centers chosen independently at random.
Charikar: Similarity Estimation Techniques from Rounding Algorithms. STOC'02.
(plný text článku)
Definuje si LSH jako rozložení, dokazuje některé vlastnosti, které má podobnostní funkce a příslušná LSH rodina. Navrhuje LSH rodiny pro vektory (kosinová míra) a Earth Mover Distance.
- Lemma 1: For any similarity function sim(x, y) that admits a locality sensitive hash function family, the distance function 1-sim(x, y) satisfies triangle inequality.
- Lemma 2: Given a locality sensitive hash function family
F corresponding to a similarity function sim(x, y), we can obtain a locality sensitive hash function family F0 that maps objects to {0, 1} and corresponds to the similarity function (1+sim(x,y))/2.
- Lemma 3: For any similarity function sim(x, y) that admits a locality sensitive hash function family, the distance function 1-sim(x, y) is isometrically embeddable in the Hamming cube.
- LSH family for vectors based on random hyperplane cutting corresponds to similarity measure (1-θ(u,v))/π which is closely related to cos(θ). If we represent sets by their characteristic vectors, we can use the random hyperplane based hash function to obtain a hash function family for set similarity, where the similarity measure of sets is 1-θ/π, where θ = cos-1(|A ∩ B|/(|A|.|B|)1/2). This hash function family facilitates easy incorporation of element weights in the similarity calculation, since the values of the coordinates of the characteristic vectors could be real valued element weights.
- Earth Mover Distance: ...
- Generalization of min-wise independent permutations to the weighted set case: we pick an infinite sequence {(it, αt)}, t=1, ..., ∞ where for each t, it is picked uniformly and at random in {1, . . . n} and αt is picked uniformly and at random in [0, 1]. Given a distribution P = (p1, . . . , pn), the assignment of labels is done in phases. In the ith phase, we check whether αi ≤ pit. If this is the case and P has not been assigned a label yet, it is assigned label it.
Gionis, Indyk, Motwani: Similarity Search In High Dimensions via Hashing. VLDB'99.
(plný text článku)
Lv, Josephson, Wang, Charikar, Li: Multi-Probe LSH: Efficient Indexing for High-Dimensional Similarity Search. VLDB'07.
(plný text článku)
Slabinou klasických LSH přístupů je, že pro dosažení rozumné přesnosti potřebují pro velké objemy dat hodně hashovacích tabulek. Multi-Probe LSH navrhuje lépe využít tabulky (přistupovat do více než jednoho bucketu) a tím snížit potřebný počet tabulek. Pro konkrétní metriku (d-dimenzionální vektory, projekce do přímky) se navrhuje postup procházení bucketů.
- Properties of ideal indexing scheme for similarity search:
- Accurate: A query operation should return desired results that are very close to those of the brute-force, linear-scan approach.
- Time efficient: A query operation should take O(1) or
O(logN) time where N is the number of data objects in the dataset.
- Space efficient: An index should require a very small amount of space, ideally linear in the dataset size, not much larger than the raw data representation. For reasonably large datasets, the index data structure may
even fit into main memory.
- High-dimensional: The indexing scheme should work well for datasets with very high intrinsic dimensionalities (e.g. on the order of hundreds).
- We propose a new method called multi-probe LSH, which uses a more systematic approach to explore hash buckets. Ideally, we would like to examine the buckets with the highest success probabilities. We develop a simple approximation for these success probabilities and use it to order the hash buckets for exploration. Moreover, our ordering of hash buckets does not depend on the nearest neighbor distance as in the entropy-based approach.
- The key idea: use a carefully derived probing sequence to check multiple buckets that are likely to contain the nearest neighbors of a query
object. Given the property of locality sensitive hashing, we
know that if an object is close to a query object q but not
hashed to the same bucket as q, it is likely to be in a bucket
that is “close by” (i.e., the hash values of the two buckets
only differ slightly). Our goal is to locate these buckets.
- Two approaches: step-wise probing (try all buckets which differ in one of the L hash values g(q) = (h1(q),...,hL(q)), then buckets which differ in two values, ...) and query-directed probing (compute probability that good points are in given interval, order buckets according to these probabilities).
Novak, Batko, Zezula: Web-Scale System for Image Similarity Search: When The Dreams Are Coming True. 2008.
(plný text článku)
Škálovatelný systém pro webové vyhledávání založený na obecné metrice, využití aproximace pro získání použitelných časů. Představení M-Chordu, zkoumání parametrů aproximace.
- System is based purely on the metric space model. Using this model is a two-edged sword: (1) It provides us with a unique generality and almost absolute freedom in defining and combining the similarity measures. (2) On the other hand, indexing techniques have to abandon classic schemas and the metric searching can be less efficient, especially on simple data domains. For complex data, like the features extracted from digital images, the classic techniques may loose their performance because of high dimensionality and may have problems with efficient indexing of very large collections. The relative efficiency of the metric-based approach grows with the volume and complexity of data.
- M-Chord: scalable distributed data structure for indexing and similarity searching in metric data, based on the concept of structured P2P networks. The system has been inspired by a centralized vector-based method called iDistance – they both map the data space into a one-dimensional domain in a similar way. The M-Chord then applies one-dimensional P2P protocol, for instance Chord or Skip Graphs, in order to divide the data among the peers and to provide navigation within the system. The M-Chord search algorithms navigate the similarity queries to the relevant peers.
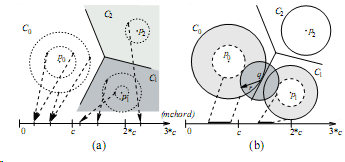
- M-Chord mapping: Several reference points (pivots, pi) are selected from the sample dataset. The data space is partitioned in a Voronoi-like manner into clusters (Ci). The one-dimensional mapping of the data objects
is defined according to their distances from the cluster’s pivot.
Having a separation constant c, the M-Chord key for an object x ∈ Ci is calculated as mchord(x) = d(pi, x) + i · c.
To evaluate a range queryR(q, r), the data space to be searched
is specified by mchord domain intervals in clusters which intersect the query region. Having the data space mapped into the mchord domain,
every active node of the system takes over responsibility for
an interval of keys. The range queries are routed to peers overlapping with the relevant intervals.
- kNN(q, k) processing:
- The query is evaluated locally on “the most promising peer(s)”; in this way, we obtain an upper bound rk on the distance to the kth nearest object from q.
- Range query R(q, rk) is executed and the k nearest objects from the
result are returned.
There is a tradeoff between the costs of the first phase and the precision of the rk estimation and, thus, cost of the second phase.
- Precise similarity searching is inherently expensive. Approximate strategy - explore only the “most promising” parts of the “most promising” clusters. The distance between the query object q and the cluster pivot d(q, pi) is taken as a heuristic of the quality of the cluster, so the algorithm visits only a specified number of clusters in the order of this distance. Within a cluster Ci, the query is first navigated to a peer responsible for key d(pi, q) + i · c, which is the most promising spot on the mchord domain for cluster Ci. This peer searches its local data, returns the partial answer to the originator, and the query is sent to some number of its adjacent peers within the cluster.
Parameters: number of clusters to visit, number of nodes to access within each cluster.
- Local data organization: Pivoting M-Tree (PM-Tree) - M-Tree with additional filtering and pruning by means of precomputed distances between the indexed objects and a fixed set of pivots. We use the same set of pivots as the M-Chord
and thus the object-pivot distances are computed only once during the insert operation.
Dong, Wang, Josephson, Charikar, Li: Modeling LSH for Performance Tuning. CIKM'08.
(plný text článku)
Statistický model pro Multi-probe LSH, který má bý adaptovatelný pro libovolnou datovou množinu a pomoci při nastavování parametrů LSH. Uvažuje se i ladění LSH pro konkrétní dotaz. Počítá se ale pouze s euklidovskou vzdáleností, pro kterou autoři vycházejí z (empirického) předpokladu, že rozložení objektů je možno popsat pomocí gama-rozložení.
Model také předpokládá použití základní LSH funkce - vynásobení náhodným vektorem, přičtení náhodného skaláru a rozdělení na úsečky.
Panigrahy: Entropy based Nearest Neighbor Search in High Dimensions. 2005.
(plný text článku)
Comments by Charikar et al. (in Multi-Probe LSH: Efficient Indexing for High-Dimensional Similarity Search):
Recent theoretical work by Panigrahy [22] proposed an entropy-based LSH scheme, which constructs its indices in a similar manner as the basic scheme, but uses a different query procedure. This scheme works as follows. Assuming we know the distance Rp from the nearest neighbor p to the query q. In principle, for every hash bucket, we can compute the probability that p lies in that hash bucket (call this the success probability of the hash bucket). Note that this distribution depends only on the distance Rp. Given this information, it would make sense to query the hash buckets which have the highest success probabilities. However, performing this calculation is cumbersome. Instead, Panigrahy proposes a clever way to sample buckets from the distribution given by these probabilities. Each time, a random point p0 at distance Rp from q is generated and the bucket that p0 is hashed to is checked. This ensures that buckets are sampled with exactly the right probabilities. Performing this sampling multiple times will ensure that all the buckets with high success probabilities are probed. However, this approach has some drawbacks: the sampling process is ineffcient because perturbing points and computing their hash values are slow, and it will inevitably generate duplicate buckets. In particular, buckets with high success probability will be generated multiple times and much of the computation is wasteful. Although it is possible to remember all buckets that have been checked previously, the overhead is high when there are many concurrent queries. Further, buckets with small success probabilities will also be generated and this is undesirable. Another drawback is that the sampling process requires knowledge of the nearest neighbor distance Rp, which is diffcult to choose in a data-dependent way. If Rp is too small, perturbed queries may not produce the desired number of objects in the candidate set. If Rp is too large, it would require many perturbed queries to achieve good search quality.
Moshfeghi, Pinto, Pollick, Jose: Understanding Relevance: An fMRI Study. ECIR 2013.
plný text článku,
bibtex
@inproceedings{DBLP:conf/ecir/MoshfeghiPPJ13,
author = {Yashar Moshfeghi and
Luisa R. Pinto and
Frank E. Pollick and
Joemon M. Jose},
title = {Understanding Relevance: An fMRI Study},
booktitle = {ECIR},
year = {2013},
pages = {14-25},
ee = {http://dx.doi.org/10.1007/978-3-642-36973-5_2},
crossref = {DBLP:conf/ecir/2013},
bibsource = {DBLP, http://dblp.uni-trier.de}
}
@proceedings{DBLP:conf/ecir/2013,
editor = {Pavel Serdyukov and
Pavel Braslavski and
Sergei O. Kuznetsov and
Jaap Kamps and
Stefan M. R{\"u}ger and
Eugene Agichtein and
Ilya Segalovich and
Emine Yilmaz},
title = {Advances in Information Retrieval - 35th European Conference
on IR Research, ECIR 2013, Moscow, Russia, March 24-27,
2013. Proceedings},
booktitle = {ECIR},
publisher = {Springer},
series = {Lecture Notes in Computer Science},
volume = {7814},
year = {2013},
isbn = {978-3-642-36972-8},
ee = {http://dx.doi.org/10.1007/978-3-642-36973-5},
bibsource = {DBLP, http://dblp.uni-trier.de}
}
Brief but wide survey of approaches to relevance feedback. They are studying the "nature of relevance" - what
happens in the brain when looking at relevant and irrelevant results.
Drucker, Shahrary, Gibbon: Support vector machines: relevance feedback and information retrieval. 2001.
(plný text článku)
Vysvětlení použití relevance feedback (iterativní vylepšování množiny vrácených dokumentů),
popis a porovnání základních algoritmů využívajících vektory (existují i jiné přístupy, např. pravděpodobnostní model).
Uživatel vždy označí nějaké dobré a špatné dokumenty ve výsledku
(ohodnotí výsledky zobrazené na první stránce, příp. několika prvních stránkách, pokud na první stránce jsou samé špatné),
podle toho se přepočítávají vyhledávací vektory.
Základní algoritmy:
- Rocchio: dokument reprezentován vektorem D, jehož velikost odpovídá počtu všech slov ve všech
dokumentech po pročištění (odstranění některých slov, hodnoty jsou 0/1/N (podle toho, jestli
slovo v daném dokumentu není, je, příp. jestli počítáme výskyty). Pomocí zvolených koeficientů
alfa, beta, gamma se vypočítá dotaz pro další iterace:
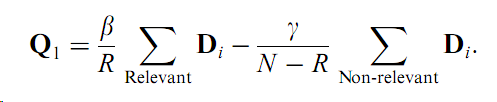
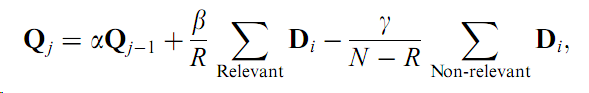
Dotaz se vynásobí s dosud nezpracovanými (neohodnocenými) dokumenty v databázi, vrací se ty s nejvyšší hodnotou. Negativní prvky
v dotazu se nastaví na nulu. Pokud bylo ve feedback hodně špatných příkladů, hodně položek bude
nulových, což další iteraci moc nepomůže.
- Ide regular:
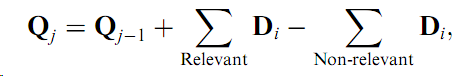
- Ide dec-hi: podobné, ale v posledním sčítanci se uvažuje jen nejvýše umístěný nerelevantní dokument.
 SVM = Support Vector Machines: hledá se nadrovina oddělující kladné a záporné případy.
Trénovací příklady se nazývají support vectors, definují dvě nadroviny, jednu pro kladné, druhou
pro záporné případy. Oddělující nadrovina se získá maximalizací jakési složité funkce.
Rozlišují se lineárně separovatelné a neseparovatelné případy. Lineární SVM se dá vyhodnotit
velmi rychle (říkají oni, pak ale uvádějí čas do tří sekund...). Jako nejlepší se po iteraci relevance feedback vrátí dokumenty, které jsou
na správné straně oddělující nadroviny a jsou od ní nejdál.
SVM = Support Vector Machines: hledá se nadrovina oddělující kladné a záporné případy.
Trénovací příklady se nazývají support vectors, definují dvě nadroviny, jednu pro kladné, druhou
pro záporné případy. Oddělující nadrovina se získá maximalizací jakési složité funkce.
Rozlišují se lineárně separovatelné a neseparovatelné případy. Lineární SVM se dá vyhodnotit
velmi rychle (říkají oni, pak ale uvádějí čas do tří sekund...). Jako nejlepší se po iteraci relevance feedback vrátí dokumenty, které jsou
na správné straně oddělující nadroviny a jsou od ní nejdál.
Dále rozebírají možnosti ohodnocení kvality. Zavrhnuty jsou precission a recall, protože to uživatel
nemůže v průběhu vyhledávání poznat a nic moc mu to neřekne. Navrhují proto "coverage ratio", což je
poměr mezi počtem zatím získaných relevantních dokumentů a počtem relevantních dokumentů, které by byly získány
pči ideálním vyhledávání. Nejlepší hodnota této metriky je 1 pro každou iteraci.
Ishikawa, Subramanya, Faloutsos: MindReader: Querying databases through multiple examples. VLDB 98.
(plný text článku)
V podstatě ani nemluví o relevance feedback, ale o multi-object dotazech, ovšem z více
vzorů se určí jeden ("ten, který uživatel chtěl") + správná distance function a podle toho
se pak vyhledává. Často citovaný článek, ovšem uvažuje jen vektory. Ideální q.o. je pak
vážený průměr vzorových objektů a distanční funkce se počítá podle toho, ve kterých deskriptorech
jsou všechny vzory blízké ideálu (ty jsou důležité, takže mají vyšší váhu) a ve kterých ne.
Autoři zdůrazňují, že jejich přístup umí podchytit i korelace mezi deskriptory.
Rui, Huang, Ortega, Mehrotra: Relevance Feedback: A Power Tool in Interactive Content-Based Image Retrieval. IEEE Trans. Circuits and Systems for Video Technology, 8(5):644–655, 1998.
(plný text článku)
Computer centric system, semantic gap, subjectivity of human perception. První návrh zavedeni relevance
feedback do podobnostního vyhledávání. Objekt modelován jako trojice (data, vlastnosti, deskriptory),
daná vlastnost může být popsána více deskriptory (histogram, color layout pro barvy),
deskriptor může být vektor. Relevance feedback má umožnit přiřadit jednotlivým vlastnostem/deskriptorům/prvkům deskriptoru
váhy podle potřeb uživatele (naopak tzv. computer centric přístup pracuje se zafixovanými vahami).
Každý z objektů v odpovědi uživatel označí jako velmi dobrý/dobrý/neutrál/špatný/velmi špatný.
Na základě toho se vyladí váhy. Na začátku musí být váhy normalizované. Pak podle toho,
jak by dopadl top-k dotaz podle dané vlastnosti, jak by se překrýval s výsledkem
combined query a které objekty uživatel označil, se přepočítají nové váhy. Uvažuje se také
to, zda se pro označené objekty daný deskriptor chová konzistentně - pokud ano, je
určující a dostane vyšší váhu. Podle všeho se při každé iteraci začíná znova od nuly
- neuvažuje se, co jsme se dověděli v minulé iteraci.
Experimenty: efficiency (rychlost konvergence algoritmu) a effectiveness (jak jsou uživatelé
spokojeni). Předpoklad pro experimenty - uživatel označuje objekty konzistentně
(to by vysvětlovalo, že ve výpočtu koeficientů nezohledňují
předchozí kroky; dá se toto ale předpokládat?). Pro efficiency používají ground
truth a zkoumají, jak rychle se k ní v jednotlivých iteracích výsledek přibližuje (zjištění:
nejvíc v první). Zkoušejí dvě skupiny objektů - jedny mají ideální nastavení vah
blíž počátečním hodnotám, druhé dál. Dále se dívají na závislost konvergence na počtu
vracených objektů - přirozeně čím víc, tím líp (víc uživatelem ohodnocených objektů).
Effectiveness - user satisfaction, ale žádné číselné vyhodnocení, pouze konstatují,
že uživatelé z různých oblastí byli velmi spokojeni.
Navrhovaná future work: zapojení textu, vylepšení výpočtu nových vah pomocí pokročilejších technik.
Zhou, Huang: Relevance feedback in image retrieval: A comprehensive review. Multimedia Systems, 2003.
(plný text článku)
Přehled různých feedback mechanismů používaných v image retrieval. Obsahuje obecná pozorování o tom, co je potřeba řešit, a popis, jaké
přístupy existují.
- We need a user-in-the-loop, because images reside in a continuous representation space, inwhich semantic concepts are best described in discriminative subspaces – “cars” are of certain shapewhile “sunset” is more describable by color. In other words, only a small subset of features (or a subspace of the original space) is active for describing any giving concept.More importantly, different users at different timesmay have different interpretations or intended usages for the same image, whichmakes off-line, user-independent learning undesirable in general.
- Since the general assumption is that every user’s need is different and time varying, a database cannot adopt a fixed clustering structure; and the total number of classes and the class membership are not available beforehand, since these are assumed to be user-dependent, and time varying as well.
- If each image/region is represented by a point in a feature space, relevance feedback with only positive examples can be cast as a density estimation or novelty detection problem. While with both positive and negative training examples it becomes a classification problem, or an online learning problem in a batch mode, but with the following characteristics:
- Small sample issue. The number of training examples is small relative to the dimension of the feature space while the number of classes is large.
- Asymmetry in training sample. The small number of negative examples is unlikely to be representative for all the irrelevant classes; thus, an asymmetric treatment may be necessary.
- Real time requirement. The algorithm should be sufficiently fast, and if possible avoid heavy computations over the whole dataset.
- Note that in reality, user consistency is hard to achieve, i.e., it is often difficult for a user to tell between two images which is “closer” to a third one consistently in accordance with the underlying feature representations adopted by the machine. In the light of this difficulty, the user modeling has to be “soft”, or probabilistic in nature.
- If we assume that the user is greedy and Impatient, and thus expects the best possible retrieval results after each feedback round, the machine should always display the most-positive images based on previous training. In this case, the user can terminate the query process at any point in time, and will always get the best results so far. Additional user feedback or “training”, if any, will be performed on these most-positive images. This is the strategy adopted by most, if not all, early relevance feedback schemes.
However, for applications where the user is co-operative and willing to provide more than one screen of training samples before seeing the results, a new question arises: “After getting feedback for one or more screens of training images, which of the remaining images shall the machine select to ask the user to label in order to achieve the highest information gain?”
The key to understanding this problem is to realize that, from the machine’s point of view, “selecting 40 examples in one batch for user labeling and training” is not as good as “selecting 20 ?rst, training on them and then selecting another 20 based on what has been learned.” In general, the most-informative images will not coincide with the most-positive images, since some of the latter might already be labeled, or tend to be very correlated with images with known labels, thus providing less new information. Intuitively, the most-informative images should be those whose labels the learner is most uncertain about.
- Objective functions and learning machines: some methods propose to learn a new query and the relative importance of different features or feature components, while others learn a linear transformation in the feature space, taking into account correlations among feature components.
- Kohonen’s learning vector quantization (LVQ) algorithm and tree-structured self-organizing map (TS-SOM). Positive and negative examples were mapped to positive and negative impulses on themaps, and a low-pass operation on the maps was argued to implicitly reveal the relative importance of different features, because a “good” map will keep positive examples cluster while negative examples scatter away.
- In Ishikawa et al. and Rui and Huang, based on the minimization of total distances of positive examples from the new query, the optimal solutions turned out to be the weighted average as the new query and a whitening transform (or Mahalanobis distance metric) in the feature space. Additionally, Rui and Huang adopted a two-level weighting scheme to better cope with singularity issue due to the small number of training samples. To take into account negative examples, Schettini et al. updated feature weights along each feature axis by comparing the variance of positive examples to the variance of the union of positive and negative examples.
- MacArthur et al. cast relevance feedback as a two-class learning problem, and used a decision tree algorithm to sequentially “cut” the feature space until all points within a partition are of the same class. The database was classified
by the resulting decision tree: images that fall into a relevant leaf were collected and nearest neighbors of the query were returned.
- Negative examples: Vasconcelos and Lippman assumed that a negative example for class Si shall be a positive example for the complement of class Si, and quantified in terms of likelihoods as follows: P(y'|Si =1)= P(y|Si =0) where y' means that y is treated as a negative example. Special steps are needed to avoid over-emphasizing the importance of negative examples.
Nastar et al. proposed empirical formulae to take into account negative examples while estimating the distribution of positive examples along each feature component. Another ad hoc formulation was proposed by Brunelli and Mich.
- Many relevance feedback algorithms make use of the sample covariance matrix and its inverse. When the number of training examples is smaller than the dimensionality of the feature space, the singularity issue arises. The substitution of the Moore–Penrose inverse or pseudo-inverse matrix for the regular inverse proposed in Ishikawa et al. is not only mathematically unfounded, but also counter-intuitive. Another proposal was to adopt a hierarchical weighting scheme (assuming a block diagonal matrix instead of the full covariance matrix) so that fewer parameters need to be estimated, and in the extreme case, just use a diagonal matrix. This implies a forced independence assumption.
- Feature normalization: Different image features need to be normalized to have comparable statistics, say normal distribution. Not surprisingly, this
normalization can also be extended to a transformation of the feature space. From a discrimination point of view, the optimal normalization shall be the transform that separates all the semantically meaningful classes in the dataset from clusters within each class. Since the class membership is not known a priori, one possible solution is to use the accumulated feedback from all the users as the training set to be fed into a multiple discriminant analysis framework to yield a transform that is optimal for the training data available so far. This implies more computation, but can give better performance than the straightforward normal distribution assumption. A simplified example is that if all users emphasize color feature more than texture in all cases, then there is no reason for maintaining equal variances along these two axes – stretching the color axis can give a better initial retrieval result.
- Incorporating textual annotations: The so-called “semantic gap” between high-level concepts in the user’s mind and low-level features extracted by the machine is so wide in many cases that the use of keywords or annotations (where available) is key to meaningful retrieval. The research efforts in combining low-level features with text include joint use of textual and visual features for querying and relevance feedback learning; learning of visual models
for concept classes annotated by keywords; and the learning of keyword relations from relevance feedback.
Shen, Jiang, Tan, Huang, Zhou: Speed up interactive image retrieval. 2008.
(plný text článku)
Autoři se snaží co nejvíce urychlit feedback loop. Zatímco ostatní se zajímají hlavně o přesnost výsledků, jim jde
i o efektivitu. Zvažují dvojí urychlení - urychlení jednotlivých iterací a snížení celkového počtu potřebných iterací. Postupují tak,
že si uchovávají informace o provedených iteracích, na základě toho odhadují průběh dalších iterací a když jsou odhady dostatečně
podobné skutečnosti, použijí je pro odhad poslední iterace. Urychlení jednotlivých iterací vznikne tak, že si spočítají překryv nové iterace
se dřívějšími a nepřistupují zbytečně již dříve přistoupené objekty.
- Feedback query refinement:
- Query point movement The query point’s coordinate values are modified iteratively based on the feedback. The
intuition of this method is to move the query point towards the good results and away from the bad ones. Ishikawa et
al. showed that the “optimal” query point is a weighted average of good results.
-
Similarity metric modification The weighted similarity metric is updated iteratively in feedback loop. The intuition
of this method is to assign higher weights to the feature components that are more important in deciding the good
results. Ishikawa et al. [16] proved that the “optimal” assignment of weight for i-th dimension at (t + 1)-th iteration
is: wt+1[i]= 1 / σt[i]^2 where σt [i] is the standard deviation of coordinates values along the i-th dimension from all the good
results at t-th iteration. Rui and Huang have extended the above technique by considering multiple features.
- The key is to maintain the information among the iterations and explore their correlations.
Search space of the refined query Qt+1 is highly likely to overlap with that of Qt. Relevance feedback
mechanisms assume that the feedback query is modified towards the “optimal” query further as more iterations are
processed. Third, queries executed in the early iterations may suggest their changing trend.
- If we know which candidate in the i th iteration will be re-accessed in the (i + 1)th iteration, we could store them
for efficient scan to avoid the expensive random accesses. Generally the number of candidates is very small compared
with the data size. And the overlap is expected to be smaler. Maintaining such a small set of candidates for efficient
scan can speed up the search. Furthermore, pre-scan on the overlap produces a potentially smaller pruning radius which
tightens the search space for the refined query.
- Overlap prediction:
- linear regression: problem - expects that the amount of change every time is fixed. However,
the changes over iterations may vary. Furthermore, the importance of past queries in linear regression
is equal in predicting the next query.
- exponential smoothing: assigns unequal weight on different data, the largest weight on the most recent data.
The exponential smoothing prediction is the weighted sum of all the past queries with the weight increasing as the iteration goes on.
One major drawback of exponential smoothing is that there is no intrinsic best value for α. To determine α, generally a set of
values are tested, and the value which best fits the queries is selected. We use the set of [0.05, 0.1, ... , 0.9, 0.95] to
choose α. Exponential smoothing tends to lag behind a trend, which causes less accurate prediction.
Exponential smoothing is appropriate when the underlying feedback queries behaves like a constant, i.e., when the mean
of queries is moving very slowly.
- linear exponential smoothing: though queries tend to get closer to the “optimal” query, the trend does not necessarily
remain constant, i.e., the trend may vary slowly over time. This could bemore convincing when more data are included.
To capture the time-varying/local trends of feedback queries, one method is to use linear (i.e., double) exponential smoothing (LES).
- adaptive linear exponential smoothing: monitors the prediction error and judges its changing trend. From
the changing trends, ALES identifies and smooth the noisy queries. A query is identified as a noise if its prediction
error exhibits a sharp up or down along the changing trend. Instead of removing
the noisy queries (we have only a few, so no removing), we smooth them by automatically replacing them with their predictions
- The KNN search in relevance feedback: Before the first step, a sequential scan is performed on the predicted overlap returned from
OptRFS. Interestingly, after sequentially scanning the predicted overlap, an initial set of results can also be computed.
And the tighter pruning radius is then passed to the first step. In the second step, random accesses are performed on the
candidates excluding those in the predicted overlap.
- Advantages: First and most interestingly, repeated random accesses on the same candidates in two consecutive
iterations are avoided. Instead, an efficient scan on the overlap leads to a much faster response. Generally, the overlap
size is much smaller than the candidate size. Manipulating overlap instead of whole candidate set in last iteration
saves both storage and scan overhead. Second, an initial set of results are computed when the sequential scan is performed
on the predicted overlap. It is potential that the initial set contain some real results. This provides a chance for phase
II to stop earlier. Let us consider the best case. When the initial set contains all real results and the lower bound of first
candidate in phase II is already greater than the Kth actual largest distance, phase II stops immediately without consuming
single random access. Third, a tighter rt is computed, which results in a smaller number of candidates. Fourth, OptRFS
is able to predict the “optimal” query so that the feedback loop can be terminated earlier. It’s noticed that OptRFS is
more effectivewhen there are indeed some considerable overlap between two iterations. While skipping many feedback
iterations improves the performance of feedback search, it
Huiskes, Lew: Performance Evaluation of Relevance Feedback Methods. CIVR’08.
(plný text článku)
Diskuze o tom, jak objektivně porovnávat RF metody. Jaké
chyby se často dělají, co je naopak vhodné.
Wu, Faloutsos, Sycara, Payne: FALCON: Feedback Adaptive Loop for Content-Based Retrieval. VLDB 2000.
(plný text článku)
Relevance feedback pro metrické prostory. Zmíněno několik metod, jak se implementuje RF,
ale vždy jen pro vektorové prostory. Oni navrhují postup pro obecné metrické prostory,
kde může být zadáno několik vzorů pro dotaz. Hledá se vhodná funkce, která bude pro každý
objekt vracet vzdálenost od množiny vzorů - "Aggregate Dissimilarity Function":
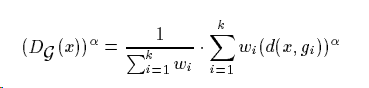
Využívá se parametr α experimentálně vyladěný pro danou datovou množinu, funkce pak
sečte vážené α-mocniny jednotlivých vzdáleností, určí průměr a ten odmocní.
Implementace je řešena pomocí více range dotazů pro jednotlivé vybrané objekty, používá se
základní vzdálenost. Je ukázáno, že nedojde k zanedbání žádného objektu. Problém je vybrat
správně range. Zmiňují možnost nechat uživatele zadat příklady, jaké nejhorší objekty by
ještě snesl, a z toho odvodit range.
Autoři v experimentech ukazují, že jejich postup vrací výsledky s vysokým precision i recall.
Zdůrazňují, že to funguje i pro výsledky, kde chceme disjunktní nebo konkávní množiny objektů,
což jiné přístupy neumí (disjunktní: několik různých množin objektů, které mají být ve výsledku;
např. fotografie prezidentů USA).
Razente, Barioni, Traina, Traina: Aggregate Similarity Queries in Relevance Feedback Methods for Content-based Image Retrieval. SAC’08.
(plný text článku)
V rámci Related work jsou dobře popsány běžné přístupy k relevance feedback, zejména
lidsky vysvětlen Rocchio algoritmus. Rozlišují single point movement přístup a multiple
point movement.
Autoři navrhují nový typ dotazu, Aggregate Similarity Query, který může mít víc než jeden
query object. Druhým parametrem je buď range, nebo k. Oba dotazy jsou formálně definovány
pomocí predikátů a podobnostní selekce (používají i zápis v relační algebře). Similarity
aggregation function převzata z Wu, Faloutsos, Sycara, Payne: FALCON: Feedback Adaptive Loop for Content-Based Retrieval.
V pokusech uvažují positive i negative feedback. Vůbec neřeší implementaci.
- To deal with the semantic gap,
relevance feedback techniques have been developed. In these
techniques, positive and/or negative examples are informed
by the user to allow the system to derive a more precise representation of the user intent. The new representation
of the user intent can be achieved through query point movement or multiple point movement techniques. Furthermore,
implicit feedback techniques have also been developed for
web search engines. In these techniques, the system learns
from search results provided by the user and takes advantage
of this information to adapt ranking functions. One way to
tell to the system what is the user’s intention is specifying,
in the same query, other elements besides the query center,
which are positive or negative examples of the intend answer.
This representation is based on multiple query centers.
- The query point movement techniques consider that a
query is represented by a single query center. Therefore
at each user interaction cycle, the strategy estimates an
ideal query center in the query space, moving the center
towards the relevant examples and away from the irrelevant
ones, as in Figure 2. When dealing with multidimensional
data, these techniques usually perform a refinement of the
dissimilarity function using the information obtained from
the user to decide which dimensions should be emphasized
and which should have their in?uence diminished. The refinement is done assigning weights to all dimensions of the
feature vector. ... It is important to note that
the query point movement creates a new feature vector that
may not correspond to an image from the dataset.
- On the other hand, multiple point movement techniques
utilize multiple query centers to represent a query, as shown
in Figure 3. The strategy of these techniques consists in as-
signing the elements informed as relevant in clusters, where
each cluster is represented by the closest element to the clus-
ter center. The new centers are called representatives, and
are used to execute a multiple center query that calculates
a single contour to cover all the representative elements. In
this type of query, it is common to use the number of elements associated to each center as its weight. ...
There are also strategies based on multiple point movement, where the elements
labeled as relevant form disjunctive clusters, thus allowing
the execution of disjunctive queries.
- We propose the generalization of the two most common similarity queries in metric spaces – the range
and the k-nearest neighbor query – defining the Aggregate Similarity Query, which retrieves elements based on their
composite similarity regarding multiple centers. An aggregate similarity query can be limited either by an aggregate
threshold t – resulting in the Aggregate Range Query – or by a quantity k of elements – resulting in the Aggregate
k-Nearest Neighbor Query
Hua, Yu, Liu: Query Decomposition: A Multiple Neighborhood Approach to Relevance Feedback Processing in Content-based Image Retrieva. ICDE’06
(plný text článku)
Celkem přehledně popsány Query Point Movement a Multipoint Query strategie pro RF.
Faginův algoritmus pro kombinované dotazy je zmíněn jako jedna z cest k vylepšení
k-nn query.
Jejich vylepšení spočívá v tom, že vytvoří R*-strom, v němž jsou objekty sdruženy
do clusterů podle podobnosti. Tento strom se tvoří zezdola.
V tom pak dělají efektivní k-nn podle více vzorů. Takové
shlukování ale myslím může fungovat jen pro vektorové prostory.
Základní dotaz se vytváří tak, že se uživateli náhodně zobrazí objekty, on vybere
relevantní, podle toho se najdou příslušné clustery a v nich se hledá.
Vu, Cheng, Hua: Image Retrieval in Multipoint Queries. 2008.
(plný text článku)
Celkem dobře popisuje jiné přístupy k multipoint query, oni ale pracují
výhradně s vektorovým prostorem, navrhují systém rovnic pro
popis vlastností, které musí být splněny pro objekty ve výsledku
(podle query objektů a hodnot jednotlivých složek jejich vektorů).
Yiu, Mamoulis: Multi-dimensional top-k dominating queries. VLDB Journal 2009.
(plný text článku)
Kombinací dvou existujících přístupů, kNN a skyline query,
vznikne top-k dominating query. Je to kNN, ale pořadí není dáno vzdáleností, kterou by
uživatel musel nějak určit a která je závislá na tom, jaké hotnoty jsou v datasetu.
Každý objekt je ohodnocen podle toho, kolika jiným
"dominuje", tj. v alespoň jedné vlastnosti je lepší a v ostatních stejně dobrý
nebo lepší.
- The top-k dominating query returns k data objects which dominate the highest number of objects in a dataset.
It combines the advantages of top-k and skyline queries without sharing their disadvantages: (i) the
output size can be controlled, (ii) no ranking functions need to be specified by users, and (iii) the result is independent of
the scales at different dimensions.
- To summarize, top-k queries do not provide an objective order of importance for the points, because their results are
sensitive to the preference function used. Skyline queries, on the other hand, only provide a subset of important points,
which may have arbitrary size. To facilitate analysts, who may be interested in a natural order of importance,
according to dominance, we propose the following intuitive score function:
τ(p) =|{ p' ∈ D | p >' p' }| (1)
In words, the score τ(p) is the number of points dominated by point p. The following monotone property holds for τ:
∀ p, p' ∈ D, p >' p': τ(p)>τ(p') (2)
Olivares, Ciaramita, Zwol. Boosting Image Retrieval through Aggregating
Search Results based on Visual Annotations. ACM Multimedia 2008.
(plný text článku)
V úvodu celkem obsáhle řeší textové
popisy Flickr a odkazují na další výzkum. Pro podobnostní vyhledávání využívají "bag-of-words" přístup,
kdy vektory jednotlivých deskriptorů převedou na slova a nad těmi pak hledají jakoby textově. Hlavní myšlenka
- uživatelé Flickru mohou přidávat tagy ke konkrétním částem obrázku, toto autoři nazývají visual annotations
- ke slovu/tagu můžu mít několik (pravděpodobně dost relevantních) ukázek. Ty používají k content-based hledání.
Spíš je to content-based search než kombinace text and visual, protože text používají jen ke získání
visual deskriptorů.
Ji, Yao, Liu, Wang, Xu. A Novel Retrieval Refinement and Interaction Pattern by
Exploring Result Correlations for Image Retrieval. 2008.
(plný text článku)
Postprocessing výsledků – shlukování podle kategorií. Používá předem kategorizované
obrázky, použitelné tedy pro databáze, kde je fixní kategorizace možná – např. medicínské obrázky.
Podle nich se určí kategorie obrázků z výsledku kNN (tzv. Pairwise-Coupling), uživateli vrátí top-k obrázků
a top-m kategorií.
Pairwise-Coupling: pro každou kategorii n klasifikátorů, ty se vyjadřují (0,1), jestli objekt
patří do kategorie (asi jestli je vzdálenost dost nízká – není přesně specifikováno). Objekt je
zařazen do té kategorie, kde získal nejvíc hlasů.
Chen, Wang, Krovetz. CLUE: Cluster-Based Retrieval of Images by Unsupervised Learning.
IEEE Transactions on Image Processing, vol. 14, no. 8, August 2005.
(plný text článku)
Postprocessing výsledků, shlukování podobných do clusterů. Funguje to tak,
že vezme množinu kandidátů (buď objekty do určitého poloměru od query, nebo top-k objektů od query
a ke každému z nich ještě top-r; u metrického prostoru to není potřeba, oni řeší i ne-metriky). Tuto
množinu si reprezentuje jako graf – objekty jsou uzly, mezi uzly hrany s ohodnocením podle vzdálenosti
(ne přímo vzdálenost, ale funkce vzdálenosti, používají
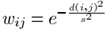 ).
).
Potom použijí grafový algoritmus na rozdělení do clusterů (normalized Cut method, variace na minimální řez).
Algoritmus dělí graf rekurzivně na dvě části, dokud není dosažen buď maximální povolený počet clusterů, nebo je
překročena nějaká hranice pro velikost řezu.
- The query image and neighboring target images, which are selected according to a similarity measure,
are clustered by an unsupervised learning method and returned to the user. In this way, relations among retrieved images are
taken into consideration through clustering and may provide for the users semantic relevant clues as to where to navigate.
- Uses a graph-theoretic algorithm to generate clusters. In particular, a set of images is represented as a weighted
undirected graph: nodes correspond to images; an edge connects two nodes; and the weight on an edge is related
to the similarity between the two nodes (or images). Graph-based representation and clustering sidestep the
restriction of a metric space.
- Graph partitioning method attempts to organize nodes into groups so that the within-group similarity is
high, and/or the between-groups similarity is low. Representative image of a cluster is the image that is most similar to
all images in the cluster.
Jia, Wang, Zhang, Hua. Finding Image Exemplars Using Fast Sparse Affinity Propagation.
Proceeding of the 16th ACM international conference on Multimedia, 2008.
(plný text článku)
Postprocessing výsledků, snaha najít reprezentativní obrázky a
ostatní shlukovat do clusterů, které jsou charakterizovány reprezentativními objekty.
Používají Sparse Affinity Propagation – opět se pracuje s grafem, ohodnocené hrany, maximalizace
podobnosti v clusteru. Zajímavé je, že pro urychlení nepracují se všemi hranami, ale některé vynechají
(proto Sparse). Hrana mezi x a y se do grafu zanese jen tehdy, pokud y patří mezi K nejbližších sousedů x.
(K se volí mnohem menší, než je počet uzlů.)
Li, Dai, Xu, Er. Multilabel Neighborhood Propagation for Region-Based Image Retrieval.
IEEE Transactions on Image Processing, 2007.
(plný text článku)
Zabývají se modelováním množiny obrázků pomocí grafu.
Ohodnocení hran na základě lokálních podobností, využívají Earth mover distance a lineární
programování. Každý obrázek může mít několik labels, řeší se šíření informací grafem.
Arampatzis, Zagoris, Chatzichristofos. Dynamic Two-Stage Image Retrieval from Large Multimodal Databases. ECIR 2011
(plný text článku)
Overview různých přístupů k rankování, valná většina používá fixní velikost initial result. Oni navrhují
jiný přístup - dynamicky měnit počet objektů podle nějakých kritérií, zejména pravděpodobnosti, že objekt
bude relevantní. Není moc jasné, jak to určují - odkazy na jiné články. Experimenty na text search a visual rank,
vyšlo jim, že dynamické prahování initial result pomáhá, uvádějí optimální nastavení parametrů.
Ambai, Yoshida. Multiclass VisualRank: Image Ranking Method in Clustered Subsets Based on Visual Features. SIGIR 09
(plný text článku)
Rozšíření VisualRanku, který často vrací příliš podobné výsledky. Multiclass VR rozdělí
výsledky dotazu do několika kategorií podle nějakých vzorů ve vizuálních deskriptorech,
v rámci kategorií se pak počítá ranking. Navrženo jako post-filtering existujích obrázkových
vyhledávání. Opět se používají SIFTy a PageRank, přidané je dělení do clusterů.
Z VR se bere podobnostní funkce, ale upraví se tak, aby se příliš vysoké hodnoty snížily
(jinak by kazily clusterování). Clustery se určují z grafu podobností pomocí normalizovaných
řezů ("normalized cuts"). Při počítání VR se pak uvažují jen hrany uvnitř clusterů.
Jing, Baluja. VisualRank: Applying PageRank to Large-Scale Image Search. IEEE TRANSACTIONS ON PATTERN ANALYSIS AND MACHINE INTELLIGENCE, November 2008
(plný text článku)
Detailní zdůvodnění, proč Google postupuje cestou nejdřív textové vyhledávání,
na výsledcích similarity ranking. Jednak je textové vyhledávání často používané a dobře
fungující, někdy také není jiný způsob, jak zadat dotaz, a konečně získá se tak různorodá
množina možných výsledků, které mohou být vstupem čistě CBIR algoritmu. Dobré porovnání
s jinými přístupy. Vysvětlení principu Eigenvector ("charakteristický vektor", pomocí kterého se počítá VisualRank.
Podobnost určují pomocí SIFTů, obecně jsou pro lokální deskriptory.
Dále autoři ukazují, jak použití VisualRank vylepší výsledek v případě a) "queries with
homogeneous visual concepts" a b) "queries with heterogeneous visual concepts". Také
stručně zmiňují problematiku možné manipulace výsledků (duplikování obrázků na stránkách).
Efektivní implementace pro web-scale search: textové vyhledávání, nad výsledkem (prvních 1000
obrázků) VisualRank. Takový přístup je query dependent - ten samý obrázek může mít v jiné
výsledkové množině jiné hodnocení. Zmíněny přístupy k rychlému porovnávání lokálních deskriptorů
(+ odkazy na literaturu), používají LSH (aproximace jim stačí) - základní vzorec pro vektory (a.V + b)/W,
pro větší přesnost zřetězí výsledky několika hashování a používají víc tabulek.
Za stejné se považují deskriptory, které mají stejný hash v alespoň C tabulkách
(používají 40 tabulek, C = 3). Pak se provázané deskriptory seřadí podle obrázků,
ke kterým patří, použijí se nějaké další úpravy a získá se výsledná podobnost obrázků.
Počítání podobnosti je výpočetně náročné, takže to nedělají online, ale předpočítávají
si výsledky pro časté dotazy! VisualRank se také využívá jen tehdy, kdy je graf podobností
dostatečně hustý.
Experimenty: a) 10 výsledků VisualRank + 10 výsledků Google search, odstranit duplikáty,
nechat uživatele označit špatné. Bez ranking, aby to uživatel neřešil. Potom se vyhodnocoval
počet nerelevantních obrázků mezi top-10, top-5 a top-3, které by vrátilo jedno a druhé vyhledávání.
b) "click measurement": předpokládá se, že uživatelé klikají na obrázky, které je zajímají.
Tohle jde ale vyhodnocovat jen díky tomu, že Google má statistiky klikání.
Jing, Baluja. PageRank for Product Image Search. WWW 2008, Beijing, China.
(plný text článku)
Vychází se z Google Image search, který vrátí počáteční množinu výsledků.
Na té se pak počítá Image Rank, a to tak, že mezi obrázky se vytváří virtuální „linky“ na základě
jejich podobnosti. Podobnost určují pomocí SIFTů. Image Rank se počítá jako Page Rank (pomocí Eigenvector),
tj. hodnocení obrázků roste tím, že ne ně odkazují (tedy jsou podobné) jiné obrázky, pokud možno také dobře hodnocené.
V tomto článku se nevažuje shlukování výsledků, ale je to zmíněno jako potřebné pro future work. Nic novějšího
o Image Rank jsem nenašla.
Při testování používají zajímavou metodu - označování výsledků, které nejsou relevantní.
- By treating images as web documents and their similarities as probabilistic visual
hyperlinks, we estimate the likelihood of images visited by a user traversing through these visual-hyperlinks. Those with
more estimated “visits” will be ranked higher than other.
- Unlike the web, where related documented are connected by manually defined hyperlinks, we compute visual-hyperlinks
explicitly as a function of the visual similarities among images. Since the graph structure will uniquely determine the
ranking of the images, our approach offers a layer of abstraction from the set of features used to compute the similarity
of the image. Similarity can be customized for the types and distributions of images expected.
- It is computationally infeasible to generate the similarity graph S for the billions of images that are indexed by
commercial search engines. One method to reduce the computational cost is to precluster web images based using metadata
such as text, anchor text, similarity or connectivity of the web pages on which they were found, etc. For example,
images associated with “Paris”, “Eiffel Tower”, “Arc de Triomphe” are more likely to share similar visual features than
random images. To make the similarity computations more tractable, a different rank can be computed for each group
of such images.
A practical method to obtain the initial set of candidates is to rely on the existing commercial search engine for the
initial grouping of semantically similar images. For example, given the query “Eiffel Tower” we can extract the top-N
reults returned, create the graph of visual similarity on the N images, and compute the image rank only on this subset.
In this instantiation, the approach is query dependent.
- Minimizing Irrelevant Images:
This study is designed to study a conservative version of “relevancy” of our ranking results. We asked the user: “Which
of the image(s) are the least relevant to the query?” For this experiment, more than 150 volunteer participants were
chosen, and were asked this question on a set of randomly chosen 50 queries selected from the top-query set. There was
no requirement on the number of images that they marked. There are several interesting points to note about this
study. First, it does not ask the user to simply mark relevant images; the reason for this is that we wanted to avoid
a heavy bias to a user’s own personal expectation (i.e. when querying “Apple” did they want the fruit or the computer?).
Second, we did not ask the users to compare two sets; since, as mentioned earlier, this is an arduous task. Instead, the
user was asked to examine each image individually. Third, the user was given no indication of ranking; thereby
alleviating the burden of analyzing image ordering.
Park, Baek, Lee: A Ranking Algorithm Using Dynamic Clustering for Content-Based Image Retrieval, 2002.
(plný text článku)
Výsledky vyhledávání se shlukují do clusterů, provede se analýza
podobnosti clusteru a query objectu, podle toho se přehodnotí uspořádání výsledků.
Uvažuje se vektorový model. Článek se dále zabývá vlivem hodnot několika parametrů
clusterování na kvalitu výsledku.
Pro vyhodnocení experimentů používají ANMMMR.
- In conventional CBIR systems, it is often observed that visually dissimilar images
to the query image are located at high ranking. To remedy this problem, we utilize similarity
relationship of retrieved results via dynamic clustering. In the first step of our method, images
are retrieved using visual feature such as color histogram, etc. Next, the retrieved images are
analyzed using a HACM (Hierarchical Agglomerative Clustering Method) and the ranking of results
is adjusted according to distance from a cluster representative to a query.
- We use Ward’s method for constructing dendrogram based on stored similarity matrix
and Lance-Williams update formula. In Ward’s method, images join the cluster that minimizes
the increase in the total within-group error sum of squares.
It relatively makes an un-biased clustering tree.
After dynamic clustering using retrieved results, we modify the distance value
ofthe results according to a equation:
D'(I,I')= αD(I,I')+ βDc(I,I')
where Dc(I,I') is distance from the query image to the cluster I'.
According to clustering hypothesis, more similar images are divided into same
cluster and irrelevant images are divided into different cluster. Distance value is
adjusted, as images in same cluster with query image have small distance value,
otherwise images have large distance value.
- We use a centroid of cluster as a cluster representative for calculating the distance
from a cluser to a query.
Park, Baek, Lee: Majority Based Ranking Approach in Web Image Retrieval, CIVR 2003.
(plný text článku)
Vylepšování výsledků získaných textovým hledáním v obrázcích. Říká se, že webové vyhledávání
v obrázcích je jiné než běžné CBIR, protože na webu jsou s obrázky spojené textové anotace.
Výsledek se tedy získá pomocí textového hledání a pak se přerankuje podle vizuální
podobnosti. Navrhují 4 metody rankování založené na clusterování prvních N výsledků
textového hledání (clusterování samozřejmě na základě vizuální podobnosti):
1) majority-first method: clustery se uspořádají podle velikosti (největší je první),
v rámci clusteru se objekty pořádají podle vzdálenosti od centroidu (průměru)
2) centroid-of-all method: ze všech objektů se spočítá centroid, objekty se řadí
podle vzdálenosti k němu
3) centroid-of-top-k method: centroid se počítá jen z prvních k prvků, pak se použije
jako query object pro rankování
4) centroid-of-largest-cluster method: v tomto případě se narozdíl od 2) a 3) ignoruje
původní uspořádání.
Pokusy nad webovými vyhledávači Google a Naver autoři zjišťují, že lépe fungují metody
1) a 4).
Brisaboa, Pedreira, Seco, Solar, Uribe: Clustering-based similarity search in metric spaces with sparse spatial centers. SOFSEM 2008.
(plný text článku)
Nieves R. Brisaboa, Oscar Pedreira, Diego Seco, Roberto Solar, and Roberto Uribe.
Clustering-based similarity search in metric spaces with sparse spatial centers. In In
34th International Conference on Current Trends in Theory and Practice of Com-
puter Science, SOFSEM, pages 186–197, Slovakia, January 19-25, 2008.
Článek o výbírání center clusterů pro indexování metrických prostorů. Obsahuje přehledné shrnutí
metrických prostorů a přístupů k indexování.
Deselaers, Keysers, Ney: Features for image retrieval: an experimental comparison. Information Retrieval, 2008.
plný text článku,
bibtex
@article {springerlink:10.1007/s10791-007-9039-3,
author = {Deselaers, Thomas and Keysers, Daniel and Ney, Hermann},
affiliation = {RWTH Aachen University Human Language Technology and Pattern Recognition, Computer Science Department Aachen Germany},
title = {Features for image retrieval: an experimental comparison},
journal = {Information Retrieval},
publisher = {Springer Netherlands},
issn = {1386-4564},
keyword = {Computer Science},
pages = {77-107},
volume = {11},
issue = {2},
url = {http://dx.doi.org/10.1007/s10791-007-9039-3},
note = {10.1007/s10791-007-9039-3},
year = {2008}
}
Kampel, Zaharieva: Recognizing Ancient Coins Based on Local Features. ISVC 2008.
(plný text článku)
Využití lokálních deskriptorů pro identifikaci mincí. Přehled základních lokálních deskriptorů,
odkazy na literaturu, srovnání výsledků různých deskriptorů pro mince (vede SIFT, problémem je rychlost).
Wu, Ke, Isard, Sun: Bundling Features for Large Scale Partial-Duplicate Web Image Search. 2009.
(plný text článku)
Vyhledávání pomocí lokálních deskriptorů, využívají shlukování několika SIFTů do tzv. "bundles",
což je víc diskriminativní a zachovává některé geometrické závislosti mezi SIFTy. Popisuje se
porovnávání shluků, které používá jednak počet stejných SIFTů, jednak jejich pozice (zhruba,
na základě jejich pořadí).
Amato, Mainetto, Savino: A Query Language for Similarity-based Retrievla of Multimedia Data. Advances in Databases and Information Systems 1997.
plný text článku,
bibtex
@article{Amato97,
author = {Giuseppe Amato and
Gianni Mainetto and
Pasquale Savino},
title = {A Query Language for Similarity-Based Retrieval of Multimedia
Data},
booktitle = {ADBIS},
year = {1997},
pages = {196-203},
ee = {db/conf/adbis/AmatoMS97.html},
crossref = {DBLP:conf/adbis/97},
bibsource = {DBLP, http://dblp.uni-trier.de}
}
@proceedings{DBLP:conf/adbis/97,
title = {Proceedings of the First East-European Symposium on Advances
in Databases and Information Systems (ADBIS'97), St.-Petersburg,
September 2-5, 1997. Volume 1: Regular Papers},
booktitle = {ADBIS},
publisher = {Nevsky Dialect},
year = {1997},
bibsource = {DBLP, http://dblp.uni-trier.de}
}
Uvažují jednak raw data content, jednak concept level – objekty na obrázku, které se nějak
rozpoznají (realizovatelný příklad – koncept person, v obrázku je/není přítomen, což určí
nějaký klasifikátor). Navrhují celkem formálně obecnou strukturu dotazu, založenou na
select-from-where. Mají operátor sim pro podobnost, ale v dotazu se nedá určit podobnostní
funkce. Mají konstanty pro vzory (red, circle).
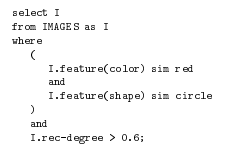
Adali, Bonatti, Sapino, Subrahmanian: A multi-similarity algebra. SIGMOD 98.
plný text článku,
bibtex
@article{Subrahmanian98,
author = {Adali, S. and Bonatti, P. and Sapino, M. L. and Subrahmanian, V. S.},
title = {A multi-similarity algebra},
journal = {SIGMOD Rec.},
volume = {27},
number = {2},
year = {1998},
issn = {0163-5808},
pages = {402--413},
doi = {http://doi.acm.org/10.1145/276305.276340},
publisher = {ACM},
address = {New York, NY, USA},
}
Universal multimedia database – various index structures, algorithms. Authors propose universal abstraction
that enables to model any (combination of any) search methods. Multi-similarity algebra MSA,
relational multi-similarity algebra rMSA. The first defines operations over similarity measures,
rMSA encapsulates this into relational algebra (new operators RSO = Relational Similarity Operator,
and Best). Very formal definitions. Furthermore, equivalences in MSA and rMSA are studied to allow
query reformulation and optimization. Cost model.
Town, Sinclair: Ontological Query Language for Content Based Image Retrieval. ANSS’03.
(plný text článku)
Jejich cílem je získat snadno použitelný vyhledávací dotaz používající přirozené
textové zadání. Vyhledávání v textových popisech + trochu CBIR (barvy, tvary v daných regionech).
Formálně popsaná bezkontextová gramatika pro popis toho, jak má vypadat výsledek
(slova, obsah obrázku, podmínky). Pro každý obrázek se na základě dotazu počítá pravděpodobnost, že
je relevantní.
some sky which is close to trees in upper corner, size at least 20%
[indoors] or [outdoors] & [people]
[some green or vividly coloured vegetation in the centre] which is of similar size as [clouds or blue
sky at the top]
Döller, Kosch, Wolf, Gruhne: Towards an MPEG-7 Query Language. SITIS 2006
(plný text článku)
Přehledný popis požadavků na QL - požadavky na systém, na jazyk.
- Požadavky na systém (framework)
- možnost kombinování dotazů nad více databázemi
- získání informací o databázi (jaké deskriptory, ...)
- Požadavky na jazyk
- Typ dotazu (Query by description, Query by example, Multimodal query, Spatial-temporal query)
- Specifikace výsledku (struktura, obsah)
- Dotazování s využitím preferencí uživatele a historie
- Specifikace velikosti a reprezentace výsledku
Dobrý, snadno srozumitelný popis základních XML dotazovacích jazyků, proč nejsou vhodné.
Jejich návrh jazyka a implementace: implementace musí podporovat sessions, které
si udržují info o uživateli a výsledcích minulých dotazů pro možnost relevance
feedback a vyhledávání v minulých výsledcích. Popis několika částí systému, jak
spolu mají komunikovat, něco jako use cases. Jazyk zde nepopisují.
Döller, Tous, Gruhne, Yoon, Sano, Burnett: The MPEG Query Format: Unifying Access to Multimedia Retrieval Systems. IEEE MultiMedia, 2008.
plný text článku,
bibtex
@article{DollerMPQF08,
author = {Mario D{\"o}ller and
Rub{\'e}n Tous and
Matthias Gruhne and
Kyoungro Yoon and
Masanori Sano and
Ian S. Burnett},
title = {The MPEG Query Format: Unifying Access to Multimedia Retrieval
Systems},
journal = {IEEE MultiMedia},
volume = {15},
number = {4},
year = {2008},
pages = {82-95},
ee = {http://doi.ieeecomputersociety.org/10.1109/MMUL.2008.96},
bibsource = {DBLP, http://dblp.uni-trier.de}
}
Dobře napsaný shrnující článek o MPEG7 Query Format.
Barioni, Razente, Traina, Traina: Seamlessly integrating similarity queries in SQL. Software - Practice and Experience, 2009
plný text článku,
bibtex
@article{DBLP:journals/spe/BarioniRTJ09,
author = {Maria Camila Nardini Barioni and
Humberto Luiz Razente and
Agma Juci Machado Traina and
Caetano Traina Jr.},
title = {Seamlessly integrating similarity queries in SQL},
journal = {Software - Practice and Experience},
volume = {39},
number = {4},
year = {2009},
pages = {355-384},
ee = {http://dx.doi.org/10.1002/spe.898},
bibsource = {DBLP, http://dblp.uni-trier.de}
}
Discussion of the need for integrating similarity queries into SQL, why user-defined functions
are not sufficient (optimization issues). Fundamental concepts: two types of objects - "particulate"
(GPS, color descriptor etc; can be compared by similarity using a distance function
defined over their constituting attributes) and "monolitic" (binary image; require extracting
predefined features that are used in place of each object to define the distance function).
The consider unary predicates (Range query, KNN query, multi-object queries) and binary predicates
(Range join, k-nearest-neighbors join, k-closest-neighbors join). Their similarity retrieval engine
is called SIREN. Contains a command interpreter that identifies similarity-based constructs and
forwards them to special processing, other parts of the query evaluated by standard RDMS.
Extensions of the SELECT command: NEAR, STOP AFTER [k], RANGE [r]. Their syntax is tailored to
the query types they consider. Further on, they describe how a new metric is defined and attached
to an attribute. User-defined parameters of searching not supported (weights, approximation),
late fusion not supported.
SELECT * FROM Employee
WHERE HomeCoordinate NEAR (
SELECT HomeLat AS Latitude, HomeLongit AS Longitude
FROM Employee WHERE name=‘John Doe’) STOP AFTER 5;
SELECT Name, FrontalMugShot FROM Employee
WHERE HomeCoordinate NEAR ALL (
SELECT HomeCoordinate FROM Employee
WHERE name like ‘% Doe’) STOP AFTER 3;
CREATE METRIC CostBenefit USING LP2 FOR PARTICULATE
(hp FLOAT 5.0, mpg FLOAT, sec FLOAT 10.0);
CREATE TABLE Cars (
CarName CHAR(35),
Horsepower FLOAT,
Consumption FLOAT,
Acceleration FLOAT,
Origin CHAR(8),
Car PARTICULATE,
METRIC REFERENCES (Horsepower AS hp,
Consumption AS mpg,
Acceleration AS sec)
USING (CostBenefit DEFAULT));
Mamou, Mass, Shmueli-Scheuer, Sznajder: A Query Language for Multimedia Content. Sigir’07.
(plný text článku)
V related work popis existujících pokusů o QL, zajímavé by mohlo být MMDOC-QL a VexQuery.
Autoři se snaží o vytvoření QL pro MPEG7 standard podporující Query-by-example. Protože MPEG7 je reprezentováno XML,
také jejich jazyk používá XML. Vychází z jazyka XML Fragments, který rozšiřuje.
Přidávají možnost ptát se na jednotlivé deskriptory, zadat jejich parametry a váhy.
Jazyk podporuje k-nn a range query.
V podstatě jde jen o podchycení toho, na co všechno se může uživatel chtít ptát.
Neuvažují multi-point query, uvažují combined. Umožňují kombinaci s textovými popisy,
podmínky na místo a čas. Nenavrhují efektivní implementaci.
<title>Twilight</Title>
<Mpeg7Query weight=”0.5”>
<VisualDescriptor type="ScalableColorType" numOfBitplanesDiscarded="0" numOfCoeff="64">
<Coeff>11 92 -3 87 … -3 -6</Coeff>
</VisualDescriptor>
</Mpeg7Query>
<Mpeg7Query weight=”2”>
<GeographicPosition>
<Point longitude="-34.7" latitude="19.75"/>
</GeographicPosition>
</Mpeg7Query>
Gruhne, Tous, Delgado, Doeller, Kosch: MP7QF: An MPEG-7 Query Format. 2007.
(plný text článku)
Jak to vypadá s QL pro MPEG7. Popis existujících snah. Prezentují committee draft pro QL,
tedy v podstatě odsouhlasený základ jazyka. Tři části - vstup (jaký typ hledání, jak má vypadat
výstup, jaké podmínky), výstup (hlášení systému, vlastní výsledek), podmínky.
<Mpeg7Query>
<Input>
<OutputDescription outputNameSpace="urn:mpeg:mpeg7:schema:2004">
<Field typeName="CreationType">/Title</Field>
</OutputDescription>
<QueryCondition>
<Condition xsi:type="QueryByFreeText">
<FreeText>Ry Cooder</FreeText>
</Condition>
</QueryCondition>
</Input>
</Mpeg7Query>
Guliato, de Melo, Rangayyan, Soares: POSTGRESQL-IE: An Image-handling Extension for PostgreSQL. Journal of Digital Imaging, Vol 22, No 2, 2009.
(plný text článku)
Některé SQL DBMS se snaží podporovat obsahové vyhledávání v obrázcích, mají sadu podporovaných
deskriptorů (každý jinou), k nim extraktory. POSTGRESQL-IE nabízí možnost definovat si vlastní
deskriptory a extraktory, vlastní kombinace apod. Článek pojat velmi prakticky, ukazuje jejich
implementaci (konkrétní používané tabulky, jak se do nich dají ukládat potřebné informace).
V podstatě ukazují velmi obecný datový model, do kterého se to dá všechno uložit.
Pracují jen s dekriptory, funcemi na jejich porovnávání a příkazy RANGE a KNN.

Pein, Lu, Renz: An Extensible Query Language for Content Based Image Retrieval based on Lucene. 2008.
(plný text článku)
Hybridní dotazovací jazyk pro text a obrázky. XML považují za zbytečně složité, jsou
pro textové dotazy založené na textovém dotazovacím jazyku Lucene. Nic moc zajímavého,
snad dvouúrovňová struktura, kde ve druhé úrovni jsou "nadstavbové" deskriptory, které
se předají k vyhodnocení příslušnému pluginu.
Natsev, Haubold, Tesic, Xie, Yan: Semantic concept-based query expansion and re-ranking for multimedia retrieval. ACM Multimedia 2007.
plný text článku,
bibtex
@inproceedings{Natsev07,
author = {Natsev, Apostol (Paul) and Haubold, Alexander and Te\v{s}i\'{c}, Jelena and Xie, Lexing and Yan, Rong},
title = {Semantic concept-based query expansion and re-ranking for multimedia retrieval},
booktitle = {Proceedings of the 15th international conference on Multimedia},
series = {MULTIMEDIA '07},
year = {2007},
isbn = {978-1-59593-702-5},
location = {Augsburg, Germany},
pages = {991--1000},
numpages = {10},
url = {http://doi.acm.org/10.1145/1291233.1291448},
doi = {http://doi.acm.org/10.1145/1291233.1291448},
acmid = {1291448},
publisher = {ACM},
address = {New York, NY, USA},
}
Related work on query expansion is the most valuable part - good categorization,
general explanation of principles.
In their application, autors aim at concept-based query expansion for video retrieval. They have set of concepts from the LSCOM-lite lexicon with
manually added annotations and links to WordNet, try to find the relevant concepts. Then get relevant
images from each concepts, join, rerank. Fusion of results from different search systems: weighted for concepts -
e.g. for some concepts, text search is known to perform better.
They use fixed text ontology and fixed visual ontology. Manual rules to map one to another.
- Most large-scale multimedia search systems typically rely on text-based search over media metadata such as surrounding html text, anchor text, titles and abstracts. This approach, however, fails when there is no such metadata (e.g., home photos and videos), when the rich link structure of the Web cannot be exploited (e.g., enterprise content and archives), or when the metadata cannot precisely capture the true multimedia content.
- On the other extreme, there has been a substantial body of work in the research community on content-based retrieval methods by leveraging the query-by-example and relevance feedback paradigms. These methods do not require any additional metadata, but rely on users to express their queries in terms of query examples with low-level features such as colors, textures and shapes. Finding appropriate examples, however, is not easy, and it is still quite challenging to capture the user intent with just a few examples.
- Lexical approaches leverage global language properties, such as synonyms and other linguistic word relationships (e.g., hypernyms). These approaches are typically based on dictionaries or other similar knowledge representation sources such as WordNet [38]. Lexical query expansion approaches can be effective in improving recall but word sense ambiguity can frequently lead to topic drift, where the semantics of the query changes as additional terms are added.
- They use LSCOM-lite lexicon and prepare SVM models for each of the concepts is the lexicon. Concepts manually annotated, linked to WordNet synsets. For query image, they evaluate each of the models, get weights for concepts
Eickhoff, Li, de Vries: Exploiting User Comments for Audio-Visual Content Indexing and Retrieval. ECIR 2013
plný text článku,
bibtex
@inproceedings{DBLP:conf/ecir/EickhoffLV13,
author = {Carsten Eickhoff and
Wen Li and
Arjen P. de Vries},
title = {Exploiting User Comments for Audio-Visual Content Indexing
and Retrieval},
booktitle = {ECIR},
year = {2013},
pages = {38-49},
ee = {http://dx.doi.org/10.1007/978-3-642-36973-5_4},
crossref = {DBLP:conf/ecir/2013},
bibsource = {DBLP, http://dblp.uni-trier.de}
}
@proceedings{DBLP:conf/ecir/2013,
editor = {Pavel Serdyukov and
Pavel Braslavski and
Sergei O. Kuznetsov and
Jaap Kamps and
Stefan M. R{\"u}ger and
Eugene Agichtein and
Ilya Segalovich and
Emine Yilmaz},
title = {Advances in Information Retrieval - 35th European Conference
on IR Research, ECIR 2013, Moscow, Russia, March 24-27,
2013. Proceedings},
booktitle = {ECIR},
publisher = {Springer},
series = {Lecture Notes in Computer Science},
volume = {7814},
year = {2013},
isbn = {978-3-642-36972-8},
ee = {http://dx.doi.org/10.1007/978-3-642-36973-5},
bibsource = {DBLP, http://dblp.uni-trier.de}
}
They analyze user comments of YouTube videos to retrieve relevant tags. For this type of data,
a high level of noise is typical, they suggest how to deal with that using time dimension.
Related work on keyword mining techniques. Their main idea - identify "bursts" of informative
comments (assumption: many comments in short time span contain more information that other
random comments). Also a few comments before each burst are deemed interesting.
The burst strategy aims at eliminating unrelated and uninformative comments. The second
source of noise are misspellings, abbreviations, chatspeak and foreign language utterances.
They use Wikipedia to deal with these: terms that do not have a dedicated article in the
English version of Wikipedia are assumed to be noise. Large-scale experiments, relevance
judgements via crowdsourcing (Amazon Mechanical Turk), majority vote.
- ... The promising results achieved by previous work
support the feasibility of our goal: Describing content exclusively based on user
comments. We will employ statistical language models aided by time series analyses
and external web resources such as Wikipedia, to find potential index terms
and evaluate their quality in a series of TREC-style experiments.
- The previous sections detailed concrete, task-driven performance evaluations of
our method. In this section, we will dedicate some room to lessons learned and
will discuss several observations that could not be con?rmed to be statistically
signi?cant but yet deserve attention as they may become more salient in related
applications or domains.
Jegou, Schmid, Harzallah, Verbeek: Accurate image search using the contextual dissimilarity measure. Pattern Analysis and Machine Intelligence, 2010.
(plný text článku)
Článek se zabývá lokálními deskriptory, ale definuje zajímavou míru nepodobnosti,
která je založena na myšlence reverse kNN - dobrý výsledek je ten, který má QO také
mezi svými blízkými. Počítají vzájemnou podobnost dvou bodů pomocí průměrné vzdálenosti
ke k-tému nejbližšímu. Plus to nějak iterativně vylepšují.
Hanbury: A survey of methods for image annotation. Journal of Visual Languages & Computing, 2008.
(plný text článku),
bibtex
@article{DBLP:journals/vlc/Hanbury08,
author = {Allan Hanbury},
title = {A survey of methods for image annotation},
journal = {Journal of Visual Languages & Computing},
volume = {19},
number = {5},
year = {2008},
pages = {617-627},
ee = {http://dx.doi.org/10.1016/j.jvlc.2008.01.002},
bibsource = {DBLP, http://dblp.uni-trier.de}
}
Types of information that can be associated with images. Free-text descriptions - keywords from controlled vocabularies
- classifications based on ontologies. Levels of specificity - whole image, segments. Annotation, categorization, recognition.
Some discussion on the use of ontologies, the difficulties of creating a vocabulary for image annotation, discussion
of some existing sources (incl. WordNet). Ground truth annotation collection methods. Review of annotated image datasets
for computer vision research.
Tousch, Herbin, Audibert: Semantic hierarchies for image annotation: A survey. Pattern Recognition, 2012.
plný text článku,
bibtex
@article{DBLP:journals/pr/TouschHA12,
author = {Anne-Marie Tousch and
St{\'e}phane Herbin and
Jean-Yves Audibert},
title = {Semantic hierarchies for image annotation: A survey},
journal = {Pattern Recognition},
volume = {45},
number = {1},
year = {2012},
pages = {333-345},
ee = {http://dx.doi.org/10.1016/j.patcog.2011.05.017},
bibsource = {DBLP, http://dblp.uni-trier.de}
}
Very good survey, wide range of approaches, well structured. Nature and use of semantics in image description - semantic levels,
user and his context. Object recognition and controlled vocabularies - insights into psychological studies, links. Semantic
image analysis using unstructured vocabularies: classification of approaches (direct, linguistic, compositional, structural,
hierarchical compositional, communicating, hierarchical, multilabel). Semantic
image analysis using structured vocabularies: classification of approaches (linguistic, compositional, communicating, hierarchical).
Quite a lot of info about WordNet use. Brief section on Evaluation. Discussion of strong and weak sides of existing techniques,
future research directions: full exploitation of semantic hierarchies, multi-level and multi-faceted image interpretation, evaluation
protocols adapted to semantic hierarchy handling.
- Unstructured vocabulary
- Pros
- Generic design: all labels at the same level
- Clear but limited evaluation metrics
- Availability of evaluation databases
- Rather efficient with a limited vocabulary
- Large volume of studies in computer vision, pattern recognition and statistical learning
- Cons
- Scalability in vocabulary size not demonstrated
- No ?exibility in semantic level of description
- Algorithms are rather ‘‘Black box’’ (i.e. decisions are hard to justify)
- Noise or uncertainty in annotation not easily handled
- Mainly general category level vocabulary, not ?ne grained
- Structured vocabulary
- Pros
- Handle large vocabularies
- Can manage various levels of description or categorization, contextual phenomena, user point of view
- Can exploit knowledge based representations
- Can produce explanation of decision
- Large volume of studies in artificial intelligence, data mining and computational linguistics
- Cons
- No satisfying standard semantic hierarchy
- Evaluation metrics not finalized
- Few learning or evaluation databases available
Zhang, Islam, Lu: A review on automatic image annotation techniques. Pattern Recognition 2012
plný text článku,
bibtex
@article{ZhangIL12,
author = {Dengsheng Zhang and
Md. Monirul Islam and
Guojun Lu},
title = {A review on automatic image annotation techniques},
journal = {Pattern Recognition},
volume = {45},
number = {1},
year = {2012},
pages = {346-362},
ee = {http://dx.doi.org/10.1016/j.patcog.2011.05.013},
bibsource = {DBLP, http://dblp.uni-trier.de}
}
Motivation for artificial image annotation (AIA): searching for images. Authors focus on two aspects of AIA
- feature extraction and semantic learning/annotation. Feature extraction section: image segmentation (brief
survey of methods), survey of features in use. AIA techniques: single labelling annotation using conventional classification
methods (SVM, artificial neural network, decision tree); multi-labelling annotation, uses Bayesian methods; web-based image annotation which uses metadata to annotate images.
Rich information about the variants of machine-learning techniques and their use for annotation. Good summary of principles
and challenges of search-based annotation (here denoted as 'image annotation incorporating metadata'). Challenges
identified: 1) high dimensional feature analysis, 2) building an effective annotation model (integrate low level visual
information and high level textual information), 3) annotation and ranking problem - what to do online, what offline (with focus on keyword-based searching),
4) ranking of images within categories, 5) lack of standard vocabulary and taxonomy for annotation ("A hierarchical
modelling of image semantics is needed to categorise images properly."), 6) training and evaluation.
- "Nowadays, more and more images are available. However, to find a required image for an ordinary user
is a challenging task."
- "As annotations from text description can be noisy, these annotations need refinement. This is especially needed for
web based image annovation, because each image is usually annotated with multiple words which may not be related
to each other. In a refinement stage, it preserves the annotations which are strongly related to each other."
- "The disadvantage of Jin et al. [64] is that it depends on WordNet and thus, this approach cannot refine the annotations which do not
appear in WordNet. Wang et al. [29,32] improve the refinement process by removing the dependency on WordNet. Instead of using
WordNet, Wang et al. [29] calculate the similarity between two words as the normalised frequency of images annotated by both
words. In [32], they calculate this similarity as the normalised sum of content-similarities between the candidate image and the
images annotated by both words. The similarity values are used to find strongly correlated annotation words."
- "Another important issue is to define appropriate level of semantics. This is especially important in web image applications because
the noise in web texts is common and it is difficult to understand which annotations should be used. For example, for an image with
kangaroos, the concept ‘Australia’ is more abstract than the concepts ‘Kangaroo’. Therefore, it is necessary to identify the concepts which
have smaller semantic gap (like the concept, ‘Kangaroo’)."
- "In terms of semantic learning, there are several approaches including the traditional binary classi?cation methods, multiple
labelling methods and metadata methods. Traditional binary classification may sound attractive and straightforward but it
overlooks the fact that an image can usually be included into more than one category. Furthermore, it lacks a mechanism of
ranking images according to their similarity to the classified categories. Multiple labelling is a more reasonable approach,
because it assigns an image to several categories and assigns an image to a category with a con?dence value which assists image
ranking. All the above approaches attempt to learn higher level semantics from low level features or visual features alone. It
appears natural that metadata should be used to overcome the limitation of visual features if it is available. However, analysing
metadata is a complex matter and becomes another issue in image annotation."
Wang: A survey on automatic image annotation and trends of the new age. Procedia Engineering 2011
plný text článku
Strange short survey. Seems rather like an unfinished paper, cannot be found in DBLP. However,
there are some useful links to papers. Short discussion of three approaches to annotation: generative
models, discriminative models, graph models.
Makadia, Pavlovic, Kumar: A New Baseline for Image Annotation. 10th European Conference on Computer Vision, 2008
plný text článku,
bibtex
@inproceedings{DBLP:conf/eccv/MakadiaPK08,
author = {Ameesh Makadia and
Vladimir Pavlovic and
Sanjiv Kumar},
title = {A New Baseline for Image Annotation},
booktitle = {ECCV (3)},
year = {2008},
pages = {316-329},
ee = {http://dx.doi.org/10.1007/978-3-540-88690-7_24},
crossref = {DBLP:conf/eccv/2008-3},
bibsource = {DBLP, http://dblp.uni-trier.de}
}
@proceedings{DBLP:conf/eccv/2008-3,
editor = {David A. Forsyth and
Philip H. S. Torr and
Andrew Zisserman},
title = {Computer Vision - ECCV 2008, 10th European Conference on
Computer Vision, Marseille, France, October 12-18, 2008,
Proceedings, Part III},
booktitle = {ECCV (3)},
publisher = {Springer},
series = {Lecture Notes in Computer Science},
volume = {5304},
year = {2008},
isbn = {978-3-540-88689-1},
bibsource = {DBLP, http://dblp.uni-trier.de}
}
Automatic image annotation is a known and interesting problem, it has been researched for more than
a decade, interesting solutions exist. What is lacking is a comparison of the sophisticated techniques
to a very simple solution. Goal of this work is to create a baseline solution.
Visual similarity evaluated by global color and texture, two types of aggregation function tried.
Having nearest visual neighbors, they apply greedy label transfer algorithm.
Datasets for comparison: Corel, IAPR TC-12, web dataset with 20K images from ESP game
- "In this work, we introduce
a new baseline technique for image annotation that treats annotation as a retrieval
problem. The proposed technique utilizes low-level image features and a simple
combination of basic distances to find nearest neighbors of a given image. The
keywords are then assigned using a greedy label transfer mechanism. The proposed
baseline outperforms the current state-of-the-art methods on two standard
and one large Web dataset. We believe that such a baseline measure will provide
a strong platform to compare and better understand future annotation techniques."
- "Image annotation is a difficult task for two main reasons: First is the well-known
pixel-to-predicate or semantic gap problem, which points to the fact that it is hard to
extract semantically meaningful entities using just low level image features, e.g. color
and texture. Doing explicit recognition of thousands of objects or classes reliably is
currently an unsolved problem. The second difficulty arises due to the lack of correspondence
between the keywords and image regions in the training data. For each image, one
has access to keywords assigned to the entire image and it is not known which regions
of the image correspond to these keywords. This makes difficult the direct learning of
classifiers by assuming each keyword to be a separate class. Recently, techniques have
emerged to circumvent the correspondence problem under a discriminative multiple
instance learning paradigm [1] or a generative paradigm [2]."
- "We treat image annotation as a process of transferring keywords from nearest neighbors."
- "We propose a simple method to transfer n keywords to a query image Iq from the query’s
K nearest neighbors in the training set. Let Ii,i =1,...,K be these K nearest neighbors,
ordered by increasing distance (i.e., I1 is the most similar image). The number of
keywords associated with Ii is denoted by |Ii|. Following are the steps of our greedy
label transfer algorithm.
- Rank the keywords of I1 according to their frequency in the training set.
- 2. Of the |I1| keywords of I1, transfer the n highest ranking keywords to query Iq. If
|I1| <n, proceed to step 3.
- Rank the keywords of neighbors I2 through IK according to two factors: 1) co-
occurrence in the training set with the keywords transferred in step 2, and 2) local
frequency (i.e. how often they appear as keywords of images I2 through IK). Select
the highest ranking n -|I1| keywords to transfer to Iq."
Belém, Martins, Almeida, Gonçalves: Exploiting Novelty and Diversity in Tag Recommendation. ECIR 2013
plný text článku,
bibtex
@inproceedings{DBLP:conf/ecir/BelemMAG13,
author = {Fabiano Bel{\'e}m and
Eder Ferreira Martins and
Jussara M. Almeida and
Marcos Andr{\'e} Gon\c{c}alves},
title = {Exploiting Novelty and Diversity in Tag Recommendation},
booktitle = {ECIR},
year = {2013},
pages = {380-391},
ee = {http://dx.doi.org/10.1007/978-3-642-36973-5_32},
crossref = {DBLP:conf/ecir/2013},
bibsource = {DBLP, http://dblp.uni-trier.de}
}
@proceedings{DBLP:conf/ecir/2013,
editor = {Pavel Serdyukov and
Pavel Braslavski and
Sergei O. Kuznetsov and
Jaap Kamps and
Stefan M. R{\"u}ger and
Eugene Agichtein and
Ilya Segalovich and
Emine Yilmaz},
title = {Advances in Information Retrieval - 35th European Conference
on IR Research, ECIR 2013, Moscow, Russia, March 24-27,
2013. Proceedings},
booktitle = {ECIR},
publisher = {Springer},
series = {Lecture Notes in Computer Science},
volume = {7814},
year = {2013},
isbn = {978-3-642-36972-8},
ee = {http://dx.doi.org/10.1007/978-3-642-36973-5},
bibsource = {DBLP, http://dblp.uni-trier.de}
}
They focus on tag recommendation from texts. Interesting ideas are the quality measures
- apart from relevance, which is typically understood as the most desirable quality,
they also consider novelty and diversity (related terms; diversity = novelty of each
new term). They implement ranking function ("learning to rank" research field)
using genetic programming. Some related work on "learning to rank". They
exploit co-occurrence patterns by mining relations among tags assigned to the same object in an object collection.
Metrics for novelty and diversity: novelty is assessed as inverted frequency of a given keyword within collection,
diversity of a candidate term c with respect to a list C of candidates is estimated as the
average semantic distance between c and each other term in C. The dissimilarity between
terms t1 and t2 is measured by the relative difference between the sets of objects O1 and O2
in which they appear as tag, i.e., dist(t1,t2)= |O1-O2|/|O1∪O2|.
- Tag recommendation strategies aim at suggesting relevant and
useful keywords to users, helping them in the task of assigning tags to content.
Ultimately, these mechanisms aim at improving the quality not only of the generated
tags, by making them more complete and accurate and reducing their
noise (e.g., misspellings, unrelated words) but also of the information services
that rely on tags as data source.
Xie, He: Picture tags and world knowledge: learning tag relations from visual semantic sources. ACM Multimedia 2013:967-976
plný text článku, slidy,
bibtex
@inproceedings{DBLP:conf/smc/DuRHC12,
@inproceedings{DBLP:conf/mm/XieH13,
author = {Lexing Xie and
Xuming He},
title = {Picture tags and world knowledge: learning tag relations
from visual semantic sources},
booktitle = {ACM Multimedia},
year = {2013},
pages = {967-976},
ee = {http://doi.acm.org/10.1145/2502081.2502113},
crossref = {DBLP:conf/mm/2013},
bibsource = {DBLP, http://dblp.uni-trier.de}
}
@proceedings{DBLP:conf/mm/2013,
editor = {Alejandro Jaimes and
Nicu Sebe and
Nozha Boujemaa and
Daniel Gatica-Perez and
David A. Shamma and
Marcel Worring and
Roger Zimmermann},
title = {ACM Multimedia Conference, MM '13, Barcelona, Spain, October
21-25, 2013},
booktitle = {ACM Multimedia},
publisher = {ACM},
year = {2013},
isbn = {978-1-4503-2404-5},
ee = {http://dl.acm.org/citation.cfm?id=2502081},
bibsource = {DBLP, http://dblp.uni-trier.de}
}
Interconnecting information from Flickr (images, user tags), ImageNet and ConceptNet. They build an ImageNet/Flickr collection
by filtering ImageNet records so that only Flickr images with tags remain. On top of this collection, they compute statistics of tag use and study relationships
between tags and the relationships between tag co-occurence and semantic distance of concepts as measured by ConceptNet. They
propose some new measures of semantic relatedness and show how their resource can be used to recommend relevant tags.
Deng, Dong, Socher, Li, Li, Fei-Fei: ImageNet: A large-scale hierarchical image database. IEEE Conference on Computer Vision and Pattern Recognition, 2009
plný text článku,
bibtex
@inproceedings{DBLP:conf/cvpr/DengDSLL009,
author = {Jia Deng and
Wei Dong and
Richard Socher and
Li-Jia Li and
Kai Li and
Fei-Fei Li},
title = {ImageNet: A large-scale hierarchical image database},
booktitle = {CVPR},
year = {2009},
pages = {248-255},
ee = {http://doi.ieeecomputersociety.org/10.1109/CVPRW.2009.5206848},
crossref = {DBLP:conf/cvpr/2009},
bibsource = {DBLP, http://dblp.uni-trier.de}
}
@proceedings{DBLP:conf/cvpr/2009,
title = {2009 IEEE Computer Society Conference on Computer Vision
and Pattern Recognition (CVPR 2009), 20-25 June 2009, Miami,
Florida, USA},
booktitle = {CVPR},
publisher = {IEEE},
year = {2009},
isbn = {978-1-4244-3992-8},
bibsource = {DBLP, http://dblp.uni-trier.de}
}
Koncepce ImageNetu, postup tvorby (text-search pomocí slov ze synsetu + nějaké rozšíření o slova z nadřazených synsetů, verifikace lidmi přes Mechanical Turk), možnosti využití.
Porovnání s jinými existujícími databázemi obrázků - dobré pro přehled, co existuje (Caltech, MSRC, PASCAL, TinyImage, ESP dataset, LabelMe, Lotus Hill).
Du, Rau, Huang, Chen: Improving the quality of tags using state transition on progressive image search and recommendation system. SMC 2012
plný text článku,
bibtex
@inproceedings{DBLP:conf/smc/DuRHC12,
author = {Wen-Hau Du and
Jer-Wei Rau and
Jen-Wei Huang and
Yung-Sheng Chen},
title = {Improving the quality of tags using state transition on
progressive image search and recommendation system},
booktitle = {SMC},
year = {2012},
pages = {3233-3238},
ee = {http://dx.doi.org/10.1109/ICSMC.2012.6378289},
crossref = {DBLP:conf/smc/2012},
bibsource = {DBLP, http://dblp.uni-trier.de}
}
@proceedings{DBLP:conf/smc/2012,
title = {Proceedings of the IEEE International Conference on Systems,
Man, and Cybernetics, SMC 2012, Seoul, Korea (South), October
14-17, 2012},
booktitle = {SMC},
publisher = {IEEE},
year = {2012},
isbn = {978-1-4673-1713-9},
ee = {http://ieeexplore.ieee.org/xpl/mostRecentIssue.jsp?punumber=6362338},
bibsource = {DBLP, http://dblp.uni-trier.de}
}
Selecting relevant tags from Flickr-like galleries with user tagging. "Waking And Sleeping algorithm", uses number of clicks.
Short survey of other tag cleaning methods.
Sun, Bhowmick, Chong: Social image tag recommendation by concept matching. ACM Multimedia 2011
plný text článku,
bibtex
@inproceedings{DBLP:conf/mm/SunBC11,
author = {Aixin Sun and
Sourav S. Bhowmick and
Jun-An Chong},
title = {Social image tag recommendation by concept matching},
booktitle = {ACM Multimedia},
year = {2011},
pages = {1181-1184},
ee = {http://doi.acm.org/10.1145/2072298.2071969},
crossref = {DBLP:conf/mm/2011},
bibsource = {DBLP, http://dblp.uni-trier.de}
}
@proceedings{DBLP:conf/mm/2011,
editor = {K. Sel\c{c}uk Candan and
Sethuraman Panchanathan and
Balakrishnan Prabhakaran and
Hari Sundaram and
Wu-chi Feng and
Nicu Sebe},
title = {Proceedings of the 19th International Conference on Multimedia
2011, Scottsdale, AZ, USA, November 28 - December 1, 2011},
booktitle = {ACM Multimedia},
publisher = {ACM},
year = {2011},
isbn = {978-1-4503-0616-4},
bibsource = {DBLP, http://dblp.uni-trier.de}
}
Abstract: Tags associated with social images are valuable information source for
superior image search and retrieval experiences. In this paper, we propose a novel tag recommendation
technique that exploits the user-given tags associated with images. Each candidate tag to be recommended
is described by a few tag concepts derived from the collective knowledge embedded in the tag co-occurrence
pairs. Each concept, represented by a few tags with high co-occurrences among themselves, is indexed
as a textual document. Then user-given tags of an image is represented as a text query and the
matching concepts are retrieved from the index. The candidate tags associated with the matching
concepts are then recommended. Leverages on the well studied Information Retrieval (IR) techniques,
the proposed approach leads to superior tag recommendation accuracy and lower execution time compared to the state-of-the-art.
Lux, Pitman, Marques: Can Global Visual Features Improve Tag Recommendation for Image Annotation? Future Internet 2010
plný text článku,
bibtex
@article{DBLP:journals/fi/LuxPM10,
author = {Mathias Lux and
Arthur Pitman and
Oge Marques},
title = {Can Global Visual Features Improve Tag Recommendation for
Image Annotation?},
journal = {Future Internet},
volume = {2},
number = {3},
year = {2010},
pages = {341-362},
ee = {http://dx.doi.org/10.3390/fi2030341},
bibsource = {DBLP, http://dblp.uni-trier.de}
}
Content-aware tag recommendation, rich related work on tag recommendation. Some considerations about tagging habbits
o users. Their own idea rather simple:
start with some user-provided tags, evaluate a text search,
take the result and reorder by visual similarity, take n best images, combine their tags, select the most
relevant ones. For visual similarity,
they use Color and Edge Directivity Descriptor, which is claimed to be better that the MPEG7 ones.
- The goal of the research efforts described in this paper is to improve annotation quality and quantity
(i.e., increase the number of meaningful tags assigned to an image) by tag recommendation. This was
accomplished by developing a tag recommendation system which suggests tags based both on the
context of the image and its visual contents. Rather than utilizing synthetic data or tagging
vocabularies, it attempts to leverage the “wisdom of the crowds” [8,9] by utilizing existing images and
metadata made available by online photo systems, e.g., Flickr.
- Tags may be classified into the following four broad classes:
- Tags relating to direct subject matter of the photo, i.e. describing the objects visible in the photo.
For example old town or architecture.
- Tags that provide technical information about the photo itself or the camera, such as whether a
flash was used or the particular camera model. For example nikon or i500.
- Tags describing the circumstances surrounding the photo or the emotions invoked by it. For
example awesome or speechless.
- Additional organizational tags, often pertaining to the perceived quality of the image or used to
identify individual users or groups. For example diamondclassphotographer or flickrelite.
Deselaers, Ferrari: Visual and semantic similarity in ImageNet. Computer Vision and Pattern Recognition (CVPR), 2011.
plný text článku,
bibtex
@inproceedings{DBLP:conf/cvpr/DeselaersF11,
author = {Thomas Deselaers and
Vittorio Ferrari},
title = {Visual and semantic similarity in ImageNet},
booktitle = {CVPR},
year = {2011},
pages = {1777-1784},
ee = {http://dx.doi.org/10.1109/CVPR.2011.5995474},
crossref = {DBLP:conf/cvpr/2011},
bibsource = {DBLP, http://dblp.uni-trier.de}
}
@proceedings{DBLP:conf/cvpr/2011,
title = {The 24th IEEE Conference on Computer Vision and Pattern
Recognition, CVPR 2011, Colorado Springs, CO, USA, 20-25
June 2011},
booktitle = {CVPR},
publisher = {IEEE},
year = {2011},
bibsource = {DBLP, http://dblp.uni-trier.de}
}
Na obrázcích ImageNetu zkoumají, jak moc je propojená sémantická a vizuální podobnost. Hloubka zanoření synsetu vs. vizuální variabilita objektů.
Řeší se nějaké otázky z cognitive science - basic level categories. Navrhují nový vzoreček pro výpočet podobnosti obrázků, který kombinuje
vizuální podobnosti a WordNet distance - najdou k obrázkům nejbližší z ImageNetu, podle toho počítají tu sémantickou vzdálenost. Testování
na Caltech 101 datasetu.
Heesch, Yavlinsky, Rüger: NNk Networks and Automated Annotation for Browsing Large Image Collections from the World Wide Web. Multimedia 2006.
(plný text článku)
Short paper. Obrázky jsou organizovány v jakési sociální síti, každý objekt zná objekty,
které jsou mu nějakým způsobem blízké. Dělají image annotation pomocí naučené
pravděpodobnosti, že daný vizuální projev souvisí s daným pojmem. Učí se to na
množině popsaných Corel obrázků.
Noah, Ali, Alhadi, Kassim: Going Beyond the Surrounding Text to Semantically Annotate and Search Digital Images. ACIIDS 2010.
(plný text článku)
Pracují s obrázky z novin. Snaží se (asi v rámci dané stránky, na které je obrázek)
najít pojmenované entity, na zbytek použít WordNet, ConceptNet,
hledání sémantických konceptů.
Nowak, Huiskes: New Strategies for Image Annotation: Overview of the Photo Annotation Task at ImageCLEF 2010. ImageCLEF 2011
plný text článku,
bibtex
@inproceedings{DBLP:conf/clef/NowakH10,
author = {Stefanie Nowak and
Mark J. Huiskes},
title = {New Strategies for Image Annotation: Overview of the Photo
Annotation Task at ImageCLEF 2010},
booktitle = {CLEF (Notebook Papers/LABs/Workshops)},
year = {2010},
ee = {http://clef2010.org/resources/proceedings/clef2010labs_submission_127.pdf},
crossref = {DBLP:conf/clef/2010w},
bibsource = {DBLP, http://dblp.uni-trier.de}
}
@proceedings{DBLP:conf/clef/2010w,
editor = {Martin Braschler and
Donna Harman and
Emanuele Pianta},
title = {CLEF 2010 LABs and Workshops, Notebook Papers, 22-23 September
2010, Padua, Italy},
booktitle = {CLEF (Notebook Papers/LABs/Workshops)},
year = {2010},
isbn = {978-88-904810-0-0},
ee = {http://clef2010.org/index.php?page=pages/proceedings.php},
bibsource = {DBLP, http://dblp.uni-trier.de}
}
Úkolem bylo přiřadit k obrázkům tagy z daného výběru obsahujícího 93 konceptů.
Ground truth byla získána napůl ručně (z minulého ročníku) a napůl pomocí Amazon Mechanical Turk.
Tři typy přístupů - visual, text, multimodal. Ovšem paper kromě velmi stručného popisu jednotlivých
přístupů (kdo používá které deskriptory, víceméně) obsahuje jen číselné statistiky,
žádnou rozumnou kategorizaci přístupů ani porovnání jejich vhodnosti.
Rudinac, Larson, Hanjalic: Learning Crowdsourced User Preferences for Visual Summarization of Image Collections. IEEE Transactions on Multimedia, 2013
plný text článku,
bibtex
@article{DBLP:journals/tmm/RudinacLH13,
author = {Stevan Rudinac and
Martha Larson and
Alan Hanjalic},
title = {Learning Crowdsourced User Preferences for Visual Summarization
of Image Collections},
journal = {IEEE Transactions on Multimedia},
volume = {15},
number = {6},
year = {2013},
pages = {1231-1243},
ee = {http://dx.doi.org/10.1109/TMM.2013.2261481},
bibsource = {DBLP, http://dblp.uni-trier.de}
}
- Summarization techniques, in particular, aim at providing a compact representation of a single multimedia data document or data collection.
Depending on the type of data and the application domain, summaries may consist of text, images, video segments or a combination of these.
- Paper contributions:
- We show how to deploy crowdsourcing to acquire implicit and explicit criteria humans find important when performing visual summarization
- We propose a novel approach for embedding the derived criteria into descriptive features and learning to distinguish
between images based on the likelihood of their appearance in the human-created visual summaries.
- In order to match the criteria inferred from human-created summaries, we expand the scope of features used to
represent the image collection beyond those that are typically deployed for visual summarization. This expansion
encompasses, in particular, features related to the context, aesthetic appeal, sentiment and popularity of an image.
- We provide new insights regarding the applicability of some standard image aesthetic appeal features in a general
summarization scenario.
- We demonstrate that the existence of multiple “optimal” visual summaries leads to a low inter-user agreement that
makes image set evaluation difficult. We therefore propose an automatic evaluation protocol based on the pyramid
approach and motivated by the experience from the text domain that has been documented in the literature by the text
summarization and machine translation communities.
Úvod: co jsou visual summaries, že kvalita záleží na uživateli; je tedy potřeba znát uživatele a účel
sumarizace, aby mohla být úspěšná. Obvyklé parametry, které se uvažují, jsou relevance, representativeness,
a diversity. Podle článku jsou to příliš obecné pojmy, nevíme, jak uživatelé uvažují. Toto se v článku
zkoumá prostřednictvím crowdsourcingu - na základě sumarizací, které vytvoří uživatelé, se zjišťuje, co
je pro ně důležité. Aplikace uvažovaná v článku - sumarizace geografických oblastí, používají proto geo-visual
clustering.
Z pokusů s lidmi jim vyšlo, že uživatelé se často na fotkách neshodují, ale na některých je zas shoda
nečekaně velká. Zdá se, že to závisí na aesthetic appeal, affect and sentiment, což jsou věci zkoumané
i v jiných souvislostech (computer vision, social network analytics, natural language processing).
Vyberou tedy sadu vlastností, do které zahrnou i tyto objekty, pak vezmou výsledky uživatelem
poskytnutých sumarizací a trénují SVM, aby se naučili správně rankovat obrázky v clusterech.
Clustery se vytvářejí jen pomocí geo-visual information, sentiment, líbivost a relativní kvalita
obrázku vzhledem k ostatním obrázkům se berou do úvahy až při vybírání reprezentanta clusteru.
Pro clusterování používají affinity propagation clustering, clusteruje se prvně podle geo-location,
sekundárně pomocí SIFTů (Bag of words approach).
Image aspect ratio and colorfulness emerge as the most discriminative features.
Metze, Ding, Younessian, Hauptmann: Beyond audio and video retrieval: topic-oriented multimedia summarization. International Journal of Multimedia Information Retrieval, 2013
plný text článku,
bibtex
@article{DBLP:journals/ijmir/MetzeDYH13,
author = {Florian Metze and
Duo Ding and
Ehsan Younessian and
Alexander G. Hauptmann},
title = {Beyond audio and video retrieval: topic-oriented multimedia
summarization},
journal = {IJMIR},
volume = {2},
number = {2},
year = {2013},
pages = {131-144},
ee = {http://dx.doi.org/10.1007/s13735-012-0028-y},
bibsource = {DBLP, http://dblp.uni-trier.de}
}
Transformation of videos into text summaries. Visual and audio features analyzed and classified, then templates
used to construct sentences. Currently, they focus on 10 event concepts used in TRECVID 2011 Multimedia Event Detection (MED),
for which training and test data are available. Detailed description of visual concept ranking (discard too frequent
concepts, set probability thresholds). Example output: In this video, we detected 3 or more people meeting indoors.
We probably heard the words "house", "half", "let", "happen", and "earn" in the video. We saw people sit down and we saw
body parts in the video. We probably saw food, indoor, room and adult in the video. We possivly saw 3 or more
people, joy and meeting in the video. But we also detected hand. They call the approach TOMS (topic-oriented multimedia summarization).
Possible use: efficient browsing of videos (no need to watch to decide whether relevant), explanation why a given
video was selected for a query. Evaluation: experiments with users, who performed various tasks with
videos described either by TOMS or manually. Manual descriptions were better, but TOMS results promising. Another
set of experiments tried to determine which features were most important for users.
Related work contains links to video and audio summarization papers.
Tan, Song, Liu, Xie: ImageHive: Interactive Content-Aware Image Summarization. IEEE Computer Graphics and Applications, 2012
plný text článku,
bibtex
@article{DBLP:journals/cga/TanSLX12,
author = {Li Tan and
Yangqiu Song and
Shixia Liu and
Lexing Xie},
title = {ImageHive: Interactive Content-Aware Image Summarization},
journal = {IEEE Computer Graphics and Applications},
volume = {32},
number = {1},
year = {2012},
pages = {46-55},
ee = {http://doi.ieeecomputersociety.org/10.1109/MCG.2011.89},
bibsource = {DBLP, http://dblp.uni-trier.de}
}
Zaměřují se hlavně na vizuální zpracování koláže. V úvodu poměrně hezky rozebrané cíle: 1) The image summary should be compact and make
the most salient regions in the collection visible. 2) The image layout should reflect pairwise content
relationships. 3) The summarization tool should let users examine
the image collection from multiple perspectives. Related work se týká jen zobrazování koláží. Jejich přístup - nejprve nějak vyberou reprezentanty, např. pomocí k-means,
pak ve dvou etapách řeší to rozložení. Cíle - reprezentace vztahů (podobnosti) mezi obrázky, uspořádání
obrázků tak, aby nebyly překryté dúležité části. Pro určení podobnosti používají, co je zrovna k dispozici,
takže například vizuální deskiptory, ale i WordNet-based distance of tags and descriptions. Z každého
clusteru se vybere několik reprezentantů. Pro prvotní rozložení se vybrané obrázky reprezentují uzly v grafu (hrany
reprezentují podobnost) a použije se vhodný algoritmus pro reprezentaci grafu v 2D. Článek dále rozebírá technicky
složitější a asi zajímavý problém zadefinování tvrdých a měkkých omezení, které zajistí, že důležité části obrázků
budou vidět. Evaluation - časy a výsledné koláže pro ImageHive a tři další systémy. Zkoušeli to na obrázcích z
IAPR TC-12.
- Nice intro: "Finding interesting content in a large image collection can be difficult, whether it’s photos of a friend’s
international trip or a presidential archive. One typical solution is to select a smaller set of representative images and compile
them into a compact image summary for subsequent exploration, understanding, communication, and storytelling. Organizing images
by content similarity can help users quickly locate information of interest. However, users are distracted when the informative
regions of images overlap, so summaries should avoid this. Furthermore, to deeply explore an image collection and exchange ideas,
users must be able to interact with the summary in real time."
Zheng, Herranz, Jiang: Flexible navigation in smartphones and tablets using scalable storyboards. ICMR 2013
plný text článku,
bibtex
@inproceedings{DBLP:conf/mir/ZhengHJ13,
author = {Shuai Zheng and
Luis Herranz and
Shuqiang Jiang},
title = {Flexible navigation in smartphones and tablets using scalable
storyboards},
booktitle = {ICMR},
year = {2013},
pages = {319-320},
ee = {http://doi.acm.org/10.1145/2461466.2461525},
crossref = {DBLP:conf/mir/2013},
bibsource = {DBLP, http://dblp.uni-trier.de}
}
@proceedings{DBLP:conf/mir/2013,
editor = {Ramesh Jain and
Balakrishnan Prabhakaran and
Marcel Worring and
John R. Smith and
Tat-Seng Chua},
title = {International Conference on Multimedia Retrieval, ICMR'13,
Dallas, TX, USA, April 16-19, 2013},
booktitle = {ICMR},
publisher = {ACM},
year = {2013},
isbn = {978-1-4503-2033-7},
ee = {http://dl.acm.org/citation.cfm?id=2461466},
bibsource = {DBLP, http://dblp.uni-trier.de}
}
Pro přehledné procházení kolekcí videí se často používají storyboards - sumarizace videa pomocí několika
vybraných snímků. Autoři dema představují dynamic storyboards - umožňují uživateli dynamicky měnit délku
a zaměření storyboard, aniž to stojí moc výpočetních kapacit. Dobře napsaný demo paper, chybí ale odkaz
na samotné demo.
Liu, Wang, Sun, Zheng, Tang, Shum: Picture Collage. IEEE Transactions on Multimedia, 2009
plný text článku,
bibtex
@article{DBLP:journals/tmm/LiuWSZTS09,
author = {Tie Liu and
Jingdong Wang and
Jian Sun and
Nanning Zheng and
Xiaoou Tang and
Heung-Yeung Shum},
title = {Picture Collage},
journal = {IEEE Transactions on Multimedia},
volume = {11},
number = {7},
year = {2009},
pages = {1225-1239},
ee = {http://dx.doi.org/10.1109/TMM.2009.2030741},
bibsource = {DBLP, http://dblp.uni-trier.de}
}
Asi dobrá a důkladná publikace k vytváření image collages. Cílem je "Picture
collage is a kind of visual image summary—to arrange all input
images on a given canvas, allowing overlay, to maximize visible
visual information." Řeší se tedy, jak obrázky co nejlépe naskládat na danou plochu.
Ekhtiyar, Sheida, Amintoosi: Picture Collage with Genetic Algorithm and Stereo vision. CoRR, 2012
plný text článku,
bibtex
@article{DBLP:journals/corr/abs-1201-1417,
author = {Hesam Ekhtiyar and
Mahdi Sheida and
Mahmood Amintoosi},
title = {Picture Collage with Genetic Algorithm and Stereo vision},
journal = {CoRR},
volume = {abs/1201.1417},
year = {2012},
ee = {http://arxiv.org/abs/1201.1417},
bibsource = {DBLP, http://dblp.uni-trier.de}
}
Short paper o vytváření koláží pro stereo images. Nic převratného, zajímavé jsou jen screenshoty, které ujasňují
rozdíly mezi "grid", "mosaic" a "collage".
Zhang, Huang: Hierarchical Narrative Collage For Digital Photo Album. Computer Graphics Foru, 2012
plný text článku,
bibtex
@article{DBLP:journals/cgf/ZhangH12,
author = {Lei Zhang and
Hua Huang},
title = {Hierarchical Narrative Collage For Digital Photo Album},
journal = {Comput. Graph. Forum},
volume = {31},
number = {7-2},
year = {2012},
pages = {2173-2181},
ee = {http://dx.doi.org/10.1111/j.1467-8659.2012.03210.x},
bibsource = {DBLP, http://dblp.uni-trier.de}
}
Clusterují obrázky podle místa (to odhadují podle vizuální podobnost) a času + identifikují lidi. Pak to prezentují
ve struktuře "character - setting - plot", přičemž uživatel může volit úrovně detailnosti. Hezký článek, technické
detaily jsem nestudovala. Výsledky mi nicméně na první pohled nijak skvělé nepřipadají (nezdá se mi, že by zvolená
struktura byla moc pochopitelná).
Laparra, Rigau, Vossen: Mapping WordNet to the Kyoto ontology. LREC 2012
plný text článku,
bibtex
@inproceedings{DBLP:conf/lrec/LaparraRV12,
author = {Egoitz Laparra and
German Rigau and
Piek Vossen},
title = {Mapping WordNet to the Kyoto ontology},
booktitle = {LREC},
year = {2012},
pages = {2584-2589},
ee = {http://www.lrec-conf.org/proceedings/lrec2012/summaries/908.html},
crossref = {DBLP:conf/lrec/2012},
bibsource = {DBLP, http://dblp.uni-trier.de}
}
@proceedings{DBLP:conf/lrec/2012,
editor = {Nicoletta Calzolari and
Khalid Choukri and
Thierry Declerck and
Mehmet Ugur Dogan and
Bente Maegaard and
Joseph Mariani and
Jan Odijk and
Stelios Piperidis},
title = {Proceedings of the Eighth International Conference on Language
Resources and Evaluation (LREC-2012), Istanbul, Turkey,
May 23-25, 2012},
booktitle = {LREC},
publisher = {European Language Resources Association (ELRA)},
year = {2012},
isbn = {978-2-9517408-7-7},
bibsource = {DBLP, http://dblp.uni-trier.de}
}
Kyoto is an event-mining system that tuilizes a rich knowledge model composed of wordnets and a generic ontology.
This paper describes a method of obtaining a full mapping between the English WordNet and the ontology.
The mapping was done semi-automatically.
Intro to Kyoto ontology, WordNet-to-ontology relations, mapping methodology. The result "provides a powerful
basis for semantic processing of full text in any domain".
Suchanek, Kasneci, Weikum: YAGO: A Large Ontology from Wikipedia and WordNet. Journal of Web Semantics, 2008
plný text článku,
bibtex
@article{DBLP:journals/ws/SuchanekKW08,
author = {Fabian M. Suchanek and
Gjergji Kasneci and
Gerhard Weikum},
title = {YAGO: A Large Ontology from Wikipedia and WordNet},
journal = {J. Web Sem.},
volume = {6},
number = {3},
year = {2008},
pages = {203-217},
ee = {http://dx.doi.org/10.1016/j.websem.2008.06.001},
bibsource = {DBLP, http://dblp.uni-trier.de}
}
The article presents YAGO - a large ontology with high coverage and precision that has been automatically derived from Wikipedia
and WordNet.
Griffiths, Steyvers, Firl: Google and the Mind: Predicting Fluency With PageRank. Psychological Science, 2007
plný text článku
Psychological paper, they analyze whether human mind associates concepts in a manner similar to the Google PageRank idea.
The paper nicely explains the PageRank idea in simple bud precise terms.