Tue, 28 Feb 2006
The NTP server and pool
After several years I have reviewed the configuration of our time server. I have contacted a NTP admin at CESNET (our ISP), and he pointed me to several stratum 1 NTP servers (most of them GPS-based, but there is also one server based on cesium atomic clock). So we have a fairly stable stratum 2 NTP server now, synchronized with about six stratum 1 servers, some of them outside the Czech republic.
I have also written a documentation for our users, and set up the IS MU servers to synchronize against our NTP server.
I tried to enable the X.509-based signatures of NTP data, but did not found any meaningful documentation - the "official NTP documentation" is rather confusing for me - even the NTP FAQ were more helpful. The best documentation about NTP servers is probably the Sun's "Basic NTP Administration ad Architecture" (the link is to a PDF document). However, this file documents an older revision of NTP server, without the advanced features like asymmetric cryptography.
I have added our NTP server to the public NTP server pool (which has a pleasant side-effect that we now have a free remote monitoring of the NTP server quality).
Mon, 27 Feb 2006
Scripts from the past
On Friday I was trying to modify the way IS MU cluster uses for time synchronization - it turned out that the new servers in the IS MU cluster skew the clock - the clock is about 6.5s a day faster than the reference time. (the servers are based on Tyan Tomcat boards, which are - with the exception of this problem - excellent boards).
I have looked into the script we use to glue rdate(1), hwclock(8), and system logging together. There were the following lines written near the top of the script:
# Simple front_end to rdate (1) # Nastaveni casu po siti. # Jan Kasprzak 18.10. 1994
It seems that even in 1994 there was rdate(1), hwclock(8), and I used them both on Linux systems. How old is the oldest software you wrote which is still runing on your computers?
After the Sendvič 2006
Well, 8th place at this year's Sendvič is worse than expected. However, I think we did well - there were tasks I think we would not be able to solve in the two hours limit anyway. I can recommend to look at the crossword puzzle (task 303). Most of it can be solved even by English-speaking people (only C, D, E, L, M, and N are related to the Czech language). The funniest one is probably E (at least we had a good laugh when we figured out what it was).
{kind=link}
Thu, 23 Feb 2006
Logical puzzle
My brother sent me a link to an interesting logical puzzle (in Flash, sorry). If you don't speak Japanese, here are the rules:
- The objective of the game is to transfer all persons to the other side of the river.
- The raft can hold at most two persons at a time, one of which has to be mother, father or sheriff.
- Father cannot be left alone with any of the daughters without the presence of mother.
- Mother cannot be left alone with any of the sons without the presence of father.
- The criminal cannot be left alone with any member of the family without the presence of sheriff.
- Press the blue circle button to start the game.
- Press the red button to transfer the raft with people across the river.
Good luck and try to measure how much time did you need to work out the solution, and how many steps did the solution need.
MusicPD over the Net
I use MusicPD for maintaining my audio files collection. It is nice, but it can play music to the locally connected speakers only. So it is impossible to listen to the music played by mpd from the wireless-connected laptop in the next room.
One possible solution would be to share the music collection over NFS or SMB. Another solution can be to use remote esd sound daemon and libao output of mpd.
Nevertheless, I have found something even better: the latest development version of mpd supports besides the ALSA, OSS, and libao outputs also the Icecast output. So I have created an Icecast server for our home LAN, and voila - instant music on the laptop, with no storage required. I have used the mpd and Icecast howto.
It works well, but I have to read the documentation in order to figure out a proper authentication and administration of the Icecast server, and to find out whether Icecast supports also FLAC streams (my current stream uses OGG/Vorbis).
Tue, 21 Feb 2006
Per-list spam filters
In January I received more than 40,000 spam messages. Most of them were dropped by my spam filter, but the number of messages which went to my inbox is still high. I have found that my spam filter is not working efficiently especially on messages sent through the mailing lists or aliases. I think the range of message formats, languages, encodings and so on is too broad for my spam filters.
For example, in the CRM114 Mailfilter HOWTO the author writes, that when comparing the spam and non-spam database using the cssdiff utility, the databases are quite different:
Note that there's a big difference between the two files; in this case there are about 10 times as many differences between the two files as there are similarities. That's pretty much typical.
Well, I have tried to run cssdiff on my CRM114 databases, and I have about the same number of differences as the number of similarities, not ten times more differencies than similarities, as the CRM114 author had. This means that my spam is too similar to the non-spam. Or maybe some spam going through a particular mail alias is too similar to the legitimate mail from some other alias or mailing list.
I am subscribed to many mailing lists, and I am a member of some well-known mail aliases at the University. I think some of these addresses receive mail with unique features. For example, the linux-kernel mailing list receives almost no legal mail in HTML or in Czech but occasionally somebody has a signature in Spanish or Portuguese. On the other hand, the mail alias info(a)fi.muni.cz gets many messages in Czech, Slovak, HTML-encoded, containing "suspicious" words like "account number" (for an admission fee) etc. But no Spanish almost no English messages.
It would probably make sense to have a special spam classifier database for each mailing list or alias I am member of. The drawback of this approach is that each of these databases would have to be taught the new types of spam separately. Or maybe the spam corpus for each of those addresses could be shared, and only the non-spam corpus could be separate for each address. This would probably also require some special handling such as removal the mailing list headers/footers before classification and before learning. On the positive side, the per-mailing list spam corpus could be used for filtering the mail before it enters the listserver queue (for lists which I administrate).
What do you think about it? Does anybody use a separate spam filter database for each e-mail source?
Wed, 15 Feb 2006
Why Qmail should not be used
In the local Linux mailing list somebody asked which software should he choose for the mail server. I wrote a lengthy followup on why should not Qmail be used as a MTA for new installations. I think it is a good idea to rephrase this here. This comes from a person who maintains several Qmail instalations, including the linux.cz listserver. This is not result of a short-time anger with Qmail, but rather a thought-out opinion, formed over years of Qmail usage.
Firstly, some advantages which Qmail have:
- Easy to maintain (even though it is quite different from other MTAs).
- Fast.
- Stable (which is an euphemism to "not developed anymore" :-)
- Quite secure, written by a security expert.
- Easy to write extensions for. qmail-local extracts the usually-required data from the message to the environment variables, so local delivery and filtering scripts do not need to do the hard and error-prone work.
And now the shortcomings of Qmail:
- The lack of a standard configuration procedure (i.e. GNU autotools or something similar). The author is not a good software engineer in terms that he likes to do everything himself, not using system libraries, etc. This leads to portability problems (as the h_errno problem Qmail has with newer Glibcs.
- Qmail is not Open Source. While it is free enough, the license does not allow distributing modified binaries, so that it cannot be shipped with any Linux distribution. This leads to lack of users, and slower development. Also it is not possible to distribute binaries to (for example) your customers.
- The source code is a mess (see, for example, how many times the number "100" is hard-coded in the source code).
- For long-term installations (such as linux.cz) there is a problem with the format of the queue - Qmail identifies the messages by numbers, which are taken from the inode numbers of the files themselves. So it is hard to move the queue to another volume (e.g. during the HW upgrade).
- The queue structure is relatively complicated. Tasks like "remove all of the 15_000 mails looping between a@b.cz and c@d.cz from the queue" are hard.
- Even though some things are configurable, many have a hard-coded upper limit - e.g. the maximum number of outgoing SMTP sessions: this means that after restarting Qmail, it does hardly any delivery for hours, because all remote SMTP sessions are used for retrying the old messages in the queue, which will time out anyway.
- It cannot do IPv6 (well, there are third-party patches, but they are far from complete).
- qmail-smtpd has almost no configurability, which in the present world full of spam and viruses means, that for example mails to non-existent users are accepted to the incoming queue (and the SMTP session is closed), and only then the attempt to deliver this message is made. This means that when the user does not exist, Qmail has to report the bounce to the envelope sender address, which is usually forged. So the innocent people are receiving these bounces. The correct way should be to refuse the message inside the SMTP session, without generating the bounce. Sending the false bounces can earn a well-deserved presence on the SpamCop blacklist (not to meniton that sending a random garbage to the innocent users is bad).
The latest problem is the worst one, because it is a design problem - it is a shortcoming of Qmail's modularity. It cannot be solved without rewriting qmail-smtpd (but that would require that it can access the database of users/aliases/etc., so it would have to leave its chroot jail).
So my recommendation is: do not use qmail for new installations. Choose Postfix or something like that instead.
Tue, 14 Feb 2006
Apache2 CPU time
Yesterday we had a huge load peak at IS MU (seminars registration or something like that). It turned out to be that we had few inoptimalities in our cluster configuration. I have spent the last night benchmarking and tweaking Apache.
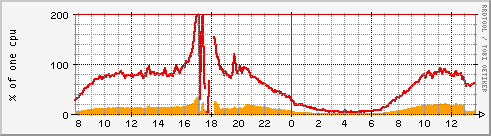
Probably the most interesting change, even visible on a MRTG graph is that I have changed the SSL session cache from DBM to the shared memory, which on our dual-core systems seem to help a bit. In the above graph the change has been made at 13:00 (the last hour on the right side). It is quite clear that both the system time (orange area) and the user time (red line) are lower in the last hour. I made the following change in httpd.conf:
-SSLSessionCache dbm:log-mu/ssl_gcache_data -SSLMutex file:log-mu/ssl_mutex +SSLSessionCache shm:log-mu/ssl_gcache_data(512000) +SSLMutex sysvsem
Fri, 10 Feb 2006
Sendvič 2006
Like last two years, even this year we will take part in Sendvič 2006 - an on-line puzzle solving competition. Our team coredump was not so bad in the previous years.
Sendvič is different from TMOU or similar competitions in that it is strictly on-line, and it is very time-limited. It is similar in style to the qualification for TMOU 7. This year the organizers of the game asked whether we would object if the next year's game is in English - so maybe next year we will have even more teams to compete with.
After two third places, I hope we have a good chance to win this year :-).
Thu, 09 Feb 2006
Van Jacobson's network channels
In DaveM's blog there is an interesting followup to the Van Jacobson's talk (slides in PDF) at linux.conf.au.
Van Jacobson suggests that the kernel networking stack should be reworked as channels (one-way lock-free queues) of packets, and the parsing and handling of the network packets is to be done as near to the end of the "food supply chain" as possible (i.e., in the user-space apps, if possible). He also gives the numbers which show the better scalability of this approach. The scalability is important especially in SMP, NUMA and multi-core systems, which are becoming more and more common these days.
While this approach is definitely interesting, Van Jacobon leaves out an important problem - how the security can be accomplished? When any app is allowed to send arbitrary packets (because it does user-space TCP), how it can be kept from interfering with other apps, disrupting other TCP connections, and so on? DaveM's suggestion is to make "channel-based" TCP in kernel, with a tiny packet classifier, which allows mapping of the packets in the device's input channel to the channel of the particular socket. The TCP handling would then be done in the context of that particular process (yet in kernel space).
Van Jacobson's measurements suggest this way the TCP processing on a SMP box can be 6 times faster (and essentially lock-free) than in the current kernel (while he also acknowledges that Linux net stack already is the fastest and most complete networking stack of any OS). There is also a LWN followup in last week's LWN "Kernel" section.
Mod_perl2 and autoflush
Another "interesting" behaviour of mod_perl2: some of our web applications set the Perl autoflush variable ($| = 1) in order to send at least partial output to client, when generating the full output can be lengthy. It seems that mod_perl2 does not like autoflush on the output filehandle.
When the autoflush is enabled, the Apache sends only the first HTTP header to the client, and the rest of the headers together with the page body is sent as a HTTP response body. Moreover, an "internal server error" message is appended afterwards.
After numerous tests I have figured out that the problem is indeed in the autoflush feature, and disabling autoflush or at least setting it after all the headers has been sent fixes the problem. I have no idea why autoflush when sending out headers is broken on mod_perl2.
Wed, 08 Feb 2006
Learning sed(1)
Few days ago I got some free time, which I decided to spend by reading the sed(1) documentation. I have used sed for tasks like s/Bill/Linus/g before, and I vaguely knew it can do something more.
Well, it turned out that the sed language is not very complicated, yet it is more powerful than I expected. It can group commands to blocks, and it can do both conditional and unconditional branches. With these constructs, the language can become powerful enough to emulate a Turing machine.
Just for fun I wrote a simple sed script which works as a context grep(1) -- i.e. it prints some context as well as the matched line (in this case, two lines above and two lines below). It has some bugs (it does not work as expected when the searched string is on two consecutive lines, for example).
#!/bin/sed -nf
# Context grep - sample script written by Jan "Yenya" Kasprzak
# The sample searched string is "gopher" here
H;x;s/.*\n\([^\n]*\n[^\n]*\n[^\n]*\)$/\1/;x# Keep the last three lines in buffer
/gopher/{x;p;x;n;N;p# If found, print the buffer, the next two lines,
# and an empty line
a
}
It can be tested with the following commands:
$ chmod +x ./agrep.sed $ ./agrep.sed /etc/passwd
For things like this, Perl or AWK would probably be a better tool, but nevertheless, using sed for something beyond the classical s/Bill/Linus/g task can be a nice mental exercise. Hmm, sed golf, anyone?
Tue, 07 Feb 2006
Computer-generated playlists
I own a decent collection of music (mostly CDs, but also vinyl and a few tapes), and I wonder whether there is a way to make the computer select what to play in any intelligent (= better than random) manner. I don't have time to "just listen" to one of my favourite albums these days, I just want some background music at work or in the car.
There are "social-network" sites such as last.fm or iRATE radio, but I think I want something different. Last.fm just suggest what other music the user may like, but I have to get it myself. iRATE radio is limited to a freely-distributable music.
Another approach are song-rating systems like PyTone (stupid name, isn't it? guess in which language is it written :-), LongPlayer, or IMMS. These can select "what to play next", but unlike the "social network" sites, it cannot suggest "what else I might like". Moreover, none of these tools seem to work with the player I use, mpd.
I think what I want is to add the rating system to the mpd back-end, and maybe a minimal rating support to the network protocol and clients (just "now play by ratings from all available songs" command, and maybe "display/change the rating of this song"). Mpd is probably flexible enough to make this working even as a separate client/daemon. The in-server solution would allow to do some neat things, though - such as per-user rating, and selecting what to play based on the ratings of all currently logged-in users.
The sad thing is that I don't have time to implement this. Anyone interested? I have created a theme for bachelors' thesis (authenticated page for MU students only, sorry) about this, so maybe some student will take this as an interesting challenge.
Sat, 04 Feb 2006
SCP only
Everybody uses SSH for secure remote logins and file transfers. The problem is that SSH sometimes allows too much. It would be nice to have a "scp-only" accounts, which could transfer files, but not run remote processes, forward ports, and so on.
I have recently found that there is a nice and clean solution to these problems: scponly is a program which can be used as the login shell for "file-transfer-only" accounts. It is also compatible with many other means of transfering files over SSH, such as rsync+ssh, Subversion over SSH, and so on.
Fri, 03 Feb 2006
Ekiga
From time to time I try to play with the IP telephony (I have mentioned it before). Now I have figured out that the GnomeMeeting team have made a big progress since then, they renamed the project to Ekiga, and they are heading to the 2.0 release.
I have installed Ekiga on my computers, and made a pair of accounts in their SIP directory at ekiga.net. Yes, Ekiga now supports also SIP in addition to H.323, which makes it an ultimate client for heterogenous environments. The ekiga.net has even some test numbers for testing things like echo, remote latency, and so on.
From my first tests it seems that Ekiga has at least as good sound level detection as Skype. The client also supports the silence detection and echo cancellation. However, the later was too weak for the environment with a huge echo, such as my laptop, which has the speakers located within few centimeters distance from the microphone. With the headphones, the calls were much more pleasant.
I have also tried the calls from behind the 1:N NAT (the laptop in my home network), with partial success. I have used the STUN server at ekiga.net, and surprisingly enough, I was able to call the internal softphone from the outside network. The other direction, however, had problems: the voice from the internal host to the outside network had too big jitter and packet loss, and the other direction did not work at all. I have to do more tests, maybe I have something set up incorrectly.
So it seems the IP telephony is getting to be pretty usable. Now I have to obtain a public phone number (either a fully public one from Netbox - my home ISP, or a "partly-public" one from CESNET, which would be suitable at least for calls to/from the University and other academic institutions).
Thu, 02 Feb 2006
Moving to Apache 2
In the last few days we have finally moved IS MU to the Apache 2.0. Well, in the meantime the 2.2 branch has been released, but we will try 2.0 first. I wrote about some problems with mod_perl2, today I will add few more:
- The SERVER_PORT environment variable is set in a different way under Apache 2.0 - with 1.3 it reflects the request's URL, with 2.0 it reflects the actual port Apache is listening on (which may be different if there is a port redirection or NAT, as in our case).
- IPC::Open3 does not work under mod_perl2. This is a known issue, with recommendation to use IPC::Run or IPC::Run3 instead. As I do not need to simultaneously write to and read from the other process, I have simply rewritten it to use the temporary files instead of IPC::Open3.
Possibly the most tricky part is that the local redirection works differently. In Apache 1.3, when the application sent out the Location: header, which was a relative or server-relative URI, the HTTP server itself issued a sub-request to that different URI, without involving the client.
In Apache 2.0, the server happily forwards the Location: header to the client, with a default status code of 200, and with an empty page body (which can confuse MSIE somewhat, I have to say :-). The internal redirects have to be called via the Apache2::SubRequest->internal_redirect() method. However, this method does not accept a fully relative URI (such as running the same script with different arguments using the myscript.pl?arg=val location). The server-relative URI has to be used instead.
Moreover, this does not work for setting a different QUERY_STRING: when the original request had a non-empty query string, it remains to be set even in the subrequest. However, for original request without the query string, the new arguments are set correctly in the subrequest. I suspect this to be a bug in CGI.pm, because I have checked that the environment variables are set correctly even in the subrequest. I have temporarily solved this by using the external redirects (with 302 status and the Location: header).
In spite of the above problems, we are now running Apache 2.0 on our production servers, and we can move on to upgrade our infrastructure to use UTF-8 even at the HTTP server layer (our DB is already in UTF-8, as I wrote before).