Tue, 19 Feb 2008
The Cost of Flexibility (and Cleanliness)
In the previously mentioned distributed computing project, I am trying to do something like the following code:
sub parse_file {
my $fh = shift;
while (my $parsed_data
= nontrivial_get_data_from($fh)) {
handle($parsed_data);
}
}
The nontrivial_get_data_from($fh) code
is indeed non-trivial (in the terms of lines of code, not necessarily
in the terms of CPU time), while handle($parsed_data)
is pretty straightforward. Now the problem is that I want to use this
non-trivial code with different handle($parsed_data)
routines (for example, printing out the $parsed_data for
testing purposes). A natural way would be to implement a pure virtual
class in which the $self->handle($parsed_data) routine
would be called inside the parse_file() method, and which
the programmer would subclass, providing different $self->handle()
implementations.
I have found that using a subclassed method $self->handle()
instead of putting the handling code directly into parse_file()
costs about 14 % of time (the dirty inlined code took 35 seconds on the
test data set, while the nice and clean subclassed one took 40 seconds).
So, my dear Perl gurus, how would you implement this? I need to call different
code in the innermost loop of the program, and just factoring it out
into the subroutine (or a virtual method) costs me about 14 % of time.
Maybe some clever eval { } and precompiling different instances
of parse_file()? In fact I don't really need the flexibility
of objects: I need only a single implementation of
handle($parsed_data) in a single program run, but I want to
be able to use a different handle() code with the
same parse_file() code base called from different programs.
Thu, 14 Feb 2008
AMD versus Intel
For a long time, we have been using AMD Opterons and Athlons 64 for our web and application servers. Everybody says that Intel has made a big progress in the last year or so, so I wondered whether an Intel architecture would be better than AMD one for our upcoming distributed computing project. Usually all benchmarks display things like raw memory throughput, encoding/decoding video (which can be done using the SIMD instructions), etc. However, how would the architectures perform on heavily branched code?
A part of our project is sorting big quantities of data. We have chunks consisting of 4-byte key, 4-byte value pairs, which have to be sorted according to the key. Since the data is being generated relatively slowly, I have decided to pre-sort it using a bucket sort into a set of 256 (for now) bucket files, then sort each bucket file separately, and finally concatenate the results. I have tried to measure how long the "sort all buckets" step will take on a single core:
| Machine | cc -Os | cc -O6 | cc -O6 w/o memcpy() |
|---|---|---|---|
| Athlon64 FX-51 2.2 GHz/1 MB L2 |
16.9s | 12.5s | 9.6s |
| Athlon64 x2 5600+ 2.8 GHz/2x 1 MB L2 |
12.5s | 8.3s | 7.1s |
| Pentium D 3.0 GHz/2 MB L2 |
9.6s | 9.0s | 8.8s |
The first two variants used memcpy() inside the quicksort routine for swapping the two entries (in order to be prepared for possible future variable data size), the last one used single 64-bit instruction instead. There are two interesting observations there:
- AMD is apparently slightly faster there.
- The
-Os(optimize for size) GCC option is useless. I wonder why it is the default optimization option for kernel compiles nowadays.
Another interesting part was the cache size effect: four biggest buckets had 1088232, 1046624, 872792, and 776224 bytes, respectively. Sorting those four buckets took 2.26, 2.22, 0.63, and 0.21 seconds (on the above FX-51 machine). This means that somewhere around 800 KB of data size, the algorithm could no longer fit the data into the L2 cache, resulting in a big slowdown: these four buckets together took more time to sort than the remaining 254 buckets, even though they contain only 2.23 % of the total data size. I guess I will just use more (512?) buckets in the production version.
So, what is your experience with compiler optimization settings, and with speed of various CPUs and architectures?
Thu, 07 Feb 2008
QR Code on a Business Card
It seems more and more phones are able to read the "2-dimensional bar codes", such as QR Code. While these codes have a widespread use mainly in Japan, they will probably become popular here as well. I have been thinking about puting one to my business card (actually, Mirka was the one who got the idea first).
 The problem is that there apparently is no standard way of formatting
contact data in the QR code. All readers I have seen so far
handle them as plain text, searching for embedded phone numbers and URLs the
same way as they do when displaying any other plain text data
(like SMS messages).
The problem is that there apparently is no standard way of formatting
contact data in the QR code. All readers I have seen so far
handle them as plain text, searching for embedded phone numbers and URLs the
same way as they do when displaying any other plain text data
(like SMS messages).
For example, the qrcode.kaywa.com
generator allows to create codes for URLs, phone numbers, or plain text.
However, the code for an URL looks exactly the same as an equivalent code
for plain text with that URL, and the code for a phone number is the same
as the code of the "TEL:that_phone_number" plain text string.
I have not found how to encode the information "the phone number of Kasprzak, Jan is +420123456789" in a way which the scanner inside the phone can understand (i.e. by adding the contact to the phonebook, including my long-and-complicated surname). Does my lazyweb know how to do this?
Wed, 06 Feb 2008
Event Library
For a distributed computing project of mine I have been looking for
a lightweight library for event-driven programming. For Perl,
I have found EV
(with EV::Watcher::Bind add-on). Now the question is
what to use for C.
I have decided to not use
glib, because it is too
heavyweight (with its own object system, etc.). The next choice was
libev, because this is what
the perl EV module is based on. And another one was
libevent, which is
already included in Fedora. Both
libev and libevent are still being actively
developed.
The most interesting thing is probably that in the
libev documentation
the author says that the glorified kqueue API on *BSD is broken
on most *BSDs (scroll down to the EVBACKEND_KQUEUE text).
I will probably use libev: it even provides an API-compatible
wrapper to libevent-based applications (does anybody know whether
it is also ABI-compatible?), and according to its author, it is
faster than libevent,
even when using the libevent API wrapper. For further reading
on why an advanced kernel API is needed instead of select(2)
or poll(2) see The C10k
problem article.
Fri, 01 Feb 2008
Spell-Checking in VIM
Mirek has asked me how do I spell-check my (preferably TeX) documents. Well, I don't, but his question made me wonder how spell-checking in Vim is done.
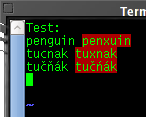
Deny has suggested this howto by Pavel Satrapa. It is basically correct, but the details are outdated. Moreover, I need something more: I usually write in three modes: English, Czech, and Czech in US-ASCII (without diacritics). So I need a Czech dictionary in ASCII.
Firstly, here is the Czech dictionary for Vim. Put it into ~/.vim/spell/ (or to a system-wide $VIMRUNTIME/spell/ - see :echo $VIMRUNTIME for the exact location).
For Czech ASCII spell-checking, I have downloaded the OpenOffice.org
data (you need the cs_CZ.zip
file). Unpack it, convert cs_CZ.dic
and cs_CZ.aff into ASCII (iconv -f iso-8859-2 -t us-ascii//TRANSLIT), rename them to (say)
csa.dic and csa.aff, run the :mkspell
csa command in vim, and move the resulting csa.utf-8.spl
file
to the same directory as the original cs.utf-8.spl.
Now set Vim to use these dictionaries using
"set spelllang=cs,en,csa" and "set spell" commands
in your ~/.vimrc, and you should
be able to test it. Remember to disable the "csa" language when writing
a document which should be strictly with diacritics. Further reading:
Vim documentation:
spell.