Fri, 29 Sep 2006
Museum of Transportation
On Thursday I went with Iva and Filip for a walk. I wanted to show Iva the old abandoned railway in Líšeň. I was very surprised when I found out that the old railway station was open, including the depository of tramways owned by the Brno Technical Museum.
They had tramways from all eras since 1900. There was even more to see there, for example MiG-21 and L-29 airplanes, some military vehicles, two or three fire brigade trucks, a model railway, etc. The most interesting thing was the 1:13 scaled model of a Škoda 22Tr trolleybus. Overall, I think I can recommend the museum, but they are just a depository, not a regular museum, so they do not have regular opening days.
3 replies for this story:
Vasek Stodulka wrote:
Hmm, interesting. And where exactly is it, please? (GPS coordinates or street name or something like this). And how do you get in? Did you ask gatekeeper or how?
Yenya wrote: Location
Look up the bus stop "Muzeum dopravy" at www.dpmb.cz (it is in Holzova street in Líšeň).
Vasek Stodulka wrote:
Thanks. They have a web page: http://www.technicalmuseum.cz/pamatky/mhd.htm. It looks like something worth of seeing, thanks for a tip.
Reply to this story:
Wed, 27 Sep 2006
Cisco woes
I've got a message from Dan saying
that Odysseus is strangely slow,
he said that copying files to Odysseus simply hanged after few kilobytes.
I have tried to run tcpdump, and it seemed that Odysseus
did not send reply to some TCP frames. After figuring out that copying
data did not work even from my workstation to Odysseus, I started to suspect
the Cisco switch, in which I have upgraded the firmware yesterday.
Yesterday I have upgraded the firmware in some of our Cisco switches (in order to finally get SSH working on them). After looking at MRTG graphs for Odysseus, I have seen something like this (it was before 2pm today):
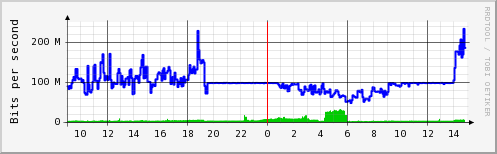
So for some reason, the link speed negotiation between Odysseus
and the Cisco switch has ended up at 100 Mbit/s FD, instead of 1 Gbit/s FD.
After restarting the negotiation using ethtool it works OK.
I hereby declare Cisco 3750 being a total crap. For example, while other switches can be rebooted in a minute or so, the boot of 3750 takes much longer, and even then, it takes another half a minute for the ethernet interfaces to become active (and it is this way even for newly plugged-in cables). Stay away from Cisco switches (at least for L2 switching, I am not familiar with their L3 gear). HP is much more open, supported, and generally better.
Sorry for the long delay between my previous post and this one. I have been off-line for 10 days, and I have been busy catching up with my mail queue since then.
14 replies for this story:
davro wrote: insufficient knowledge causes wrong results
use switchport portfast in interface config. Cisco conform exactly to specifications. All ports must be blocked for 30 sec. in learning state when running spanning tree.
davro wrote:
little mistake, use spanning-tree portfast.
davro wrote:
BTW, HP lacks many features, which are very useful in large L2 networks (PVST+, VTP, error recovery, UDLD, ...)
Danny wrote:
And did you read the documentation? It's publicly available on vendor website. I know, it's a bit longer... but deprecate something without configuration knowledge shows your disability, not some problems with that box... And by the way - c3750 is Layer3 switch... :)
Yenya wrote: Re: for davro
Hmm, bad specification then, I would say. No other vendor's default configuration does this 30-second delay. But thanks for letting me know the workaround. Funny you mention standard compliance, and then a proprietary thing like PVST+ or VTP as a Cisco advantage. We have used VTP in the past, but it was pain in the a** - for example in some of our Catalyst switches it was configured separately, outside the main config (in a "vlan database" command, IIRC). So saving a config to the TFTP server actually did not save the full state of the switch. Ugly as hell.
Yenya wrote: Re: for Danny
The Cisco documentation is one of the most disorganized pieces of data I am aware of (and I have been using various Cisco products for at least 7 years now). 3750 can do L3 switching only with a special firmware image, which we do not have. I may repeat all the Cisco drawbacks here (like no free software upgrades, messy documentation, proprietary protocols, configuration hacks like the ugly "vlan@community" hack instead of Q-BRIDGE-MIB on 4912 and 2948G, etc.). But this was not a point of my blog post. The point was that it has failed to do a correct speed autonegotiation after the reboot, and that the reboot took an exceptionally long time.
davro wrote:
30 sec. delay is failsafe default. If you don't do this, you can be suprised by spanning tree loops. Lovely to trace and debug. And if some vendor's product doesn't do this, then it fails to conform to specs (so it is a crap). And those mentioned PVST+, VTP are optional, you can easily use standard MSTP (a bit stupid IMHO) or rapid SPT.
davro wrote:
BTW: 3750 is L3 switch even with standard image. It lacks support for OSPF and other advanced L3 features.
Yenya wrote: Re: for davro
As for 3750 being an L3 switch, I did not know that. Thanks. The 30sec delay: maybe the prefered solution would be to not run any spanning tree algorithm at all by default. Those who want it can enable it manually.
davro wrote:
Yes, you can turn SPT off, but I don't think it is a way to go. It is not a safe solution. You can run into deep troubles. And 3750 is a switch for bigger networks, not a "single switch" solution, so SPT should be turned on by default.
Danny wrote:
30sec delay (by default turned STP/PVST) is standard thing on all of Cisco switches in the long term. I do not understand, why are you surprised by this thing if you say something like "I have been using various Cisco products for at least 7 years now"... this is nothing new and "specific" to Cat3750... I personally think much about your work in Linux community, but this your blogpost about Cisco gear is absolutely amateur.
sebastan wrote:
hi yenya do u know way by which we can emulate the cisco switch hardware. i mean are there any hardware or firmware debugging tools that we can use to find the internal working of the hardware as to what hardware checks it makes before it loads the ios into it. regards sebastan
nonbeginner wrote:
I hereby declare that you have to study hard first before saying that something is crap.
Yenya wrote: Re: nonbeginner
Well, I was wrong in one thing (the spanning-tree portfast problem), but long boot times, non-free firmware upgrades, and occasional autonegotiation failure remain as problems of Cisco. Feel free to enlighten me how the remaining problems do not mean Cisco 3750 is a crap.
Reply to this story:
Sun, 03 Sep 2006
Computing Server
We had problems with some users, who occasionally ran huge computing tasks on a general-purpose staff server, slowing down work for all other people (including mail server, home directories file serving, etc.). Because of this, and partly to test the technology as well, we have decided to order a separate server, which will be dedicated for such huge computing tasks (as well as for our experiments with big NUMA iron).
Yesterday the server has finally arrived. It is Tyan Transport VX50, an eight-CPU server with dualcore CPUs, 16 cores total. Apart from other things, we want to test Oracle on it. When we have bought the present IS MU database server, the biggest Opteron-based configurations had four CPUs. So we went for SGI Altix box (with 2 to 16 Itanium2 CPUs) instead. If the VX50 is stable and fast enough, our next DB server can probably be Opteron-based - who knows whether there will be SGI as a server manufacturer next year?
So far our VX50 has survived my stress-tests, including many parallel
kernel compiles, user-space variant of memtest86, filesystem
load on ext3 and XFS, etc. The hardware works, including SATA controller,
hardware sensors, etc.
77160 BogoMips[?]
in a single-image system is pretty impressive, isn't it?
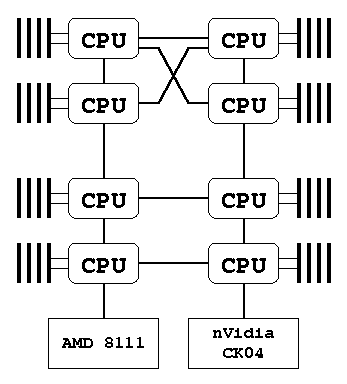
Probably the most interesting part of this server design is its NUMA topology (see above). They have managed to use all of the three HyperTransport channels of AMD 8xx CPUs, even though the configuration is not strictly symmetric then. I wonder how the routing of requests over the HT mesh is done. Does it use static routing, or some kind of load balancing? Any pointers, my dear lazyweb?
0 replies for this story:
Reply to this story:
Fri, 01 Sep 2006
The Future of NetBSD
There was an interesting thread in *BSD mailing lists, started by one of the founders of NetBSD. The thread is named The future of NetBSD, and the author states that NetBSD is losing its momentum because of the flaws in their development model (go read it now, I will wait :-).
A bit of personal history: my first UN*X on my own PC was 386BSD[?], version 0.1, then NetBSD 0.8, and for a short period also 0.9. I moved to Linux then, and never came back, altough I try to follow the news from all the *BSD projects.
In my opinion, the development model is the reason of success
of Linux. Not the enlightened leader (in terms of being superior software
designer and coder), not the support of big companies. Linus was always
open to the people who produced working code, provided that their work
did not try to rewrite everything from scratch, including few nearby
subsystems (Reiser4 :-), even though their code was not well suited for
all purposes. This is why current SATA/libata (ab)uses lots of SCSI
infrastructure, and this is why Linux has some things in /proc
and other things in /sys. But Linux has a working driver model
(including hotplug, device classes etc.), nicely coupled to the desktop
environment via HAL,
Linux has probably the best threads implementation from the free UN*Xes,
Linux had a NUMA-aware memory allocator before NetBSD even started to
implement large-grained SMP, etc.
In this sense, I can say that Linux development model follows the
Extreme programming[?] methodology:
the solution does not need to be perfect (nobody can design a perfect interface
suitable even for the hardware which is yet to be developed, for example),
but it should work and should not look obviously wrong. Using these
lightweight and not over-designed interfaces, Linux can avoid many pitfalls,
such as superfluous mid-layer (see libata or syncppp
parts of the Linux kernel for nice examples of how to avoid mid-layers,
and NetBSD DMA interface as an example of how to create them).
The openness does matter as well: the Linux kernel has patches flowing in at a rate of about 1000 changesets per week, and even though the interfaces probably gets rewritten more often than in NetBSD, they will match the actual needs of their users, not some hypothetical aestethical measures of their designers. I think the same loss of mommentum can happen also to OpenSolaris. They have a rigorous patch review process, which slows down the development. So far it seems that the main work is being done by Sun employees mostly.
I am not happy that NetBSD might be slowly dying, but I think the reasons of it are obvious: It is good to write a clean code, but it is definitely not good to let the emphasis on the design itself slow your development process down. Do not design for the future. The future will always be different, and the interfaces will have to be rewritten anyway. The closed and elitist attitude of the core developers also does not help.