Table of Contents
Idea „Sémantického webu“ byla světu poprvé prezentována v květnu roku 2001. Tim Berners-Lee, ředitel Konsorcia W3C, v časopise Scientific American upozornil, že síť www je v podstatě haldou webových stránek, která neustále roste a ve které je stále složitější nalézt relevantní informace. Situace by měla být vyřešena standardizovaným popisem všech webových zdrojů. Takovým zdrojem může být cokoliv, co je dosažitelné prostřednictvím sítě www, tedy textové dokumenty, obrázky, videosekvence, zvukové soubory apod. Každý zdroj by byl vybaven stejnými charakteristikami (autor, typ zdroje, klíčová slova atd.), což by umožnilo uživatelům internetu pracovat se sítí www jako s relační databází a dotazovat se na její obsah prostřednictvím jazyků podobných SQL. Významným důsledkem by například byla stoprocentní relevantnost odpovědi na vyhledávací dotaz, což znamená, že by byl uživateli při vyhledávání určité informace vrácen seznam všech zdrojů, které se této informace týkají, a žádný zdroj navíc. Údajům, které popisují webové zdroje, říkáme síťová metadata.
Metadata mohou být stručně definována jako „strukturovaná data o datech“. Zachycují obsah, kontext a strukturu dat, která popisují. Síťová metadata, na která se zaměříme, jsou nejčastěji zapisována prostřednictvím technologie XML, která svými vlastnostmi nejvíce odpovídá požadavkům na otevřenost, přenositelnost a interoperabilitu formátu pro výměnu a ukládání dat. Pro vyjádření vztahů mezi jednotlivými metadatovými prvky a schématy byl navržen standard RDF a skutečné zachycení sémantiky popisovaných dat je zajištěno prostřednictvím klasifikačních schémat a řízených slovníků.
Základem „Sémantického webu“ by se podle organizace W3C měl stát její standard RDF (Resource Description Framework). Podle oficiální definice jde o obecný rámec pro popis, výměnu a znovupoužití metadat. Základním přínosem RDF je zajištění interoperability na poli internetových metadat.
Rámec RDF poskytuje jednoduchý model pro popis zdrojů, který není závislý na konkrétní implementaci. Datový model RDF zjednodušeně řečeno umožní specifikovat trojice {zdroj, vlastnost, hodnota vlastnosti} s významem: „Daný zdroj má danou hodnotu dané vlastnosti“. Trojice jsou v oficiální terminologii nazývány tvrzení a v rámci daného tvrzení je zdroj subjektem, vlastnost predikátem a hodnota vlastnosti objektem. Hodnotou vlastnosti může být buď řetězec znaků (tzv. literál) nebo jiný zdroj. Tento abstraktní datový model může být využit v mnoha oblastech různými způsoby. Příkladem je vytváření katalogů popisujících obsah, usnadnění sdílení a výměny znalostí, podpora tzv. důvěryhodného webu nebo přiřazení sémantiky webovým zdrojům. My se budeme věnovat pouze poslednímu zmíněnému případu, protože právě ten je pro „Sémantický web“ klíčový.
Datový model RDF lze reprezentovat například prostřednictvím grafů či trojic, pro vyjádření sémantiky webových zdrojů se však jako nejvhodnější jeví XML syntaxe RDF (dále jen RDF/XML). RDF/XML v podstatě umožňuje přiřazení vybraných vlastností určitému webovému zdroji, případně vyjádření vztahů mezi takovými zdroji. Webovým zdrojem pak rozumíme každý objekt, kterému je přiřazen jednoznačný identifikátor ve formátu URI a který je dostupný prostřednictvím služby www. RDF/XML je vlastně jen metajazykem (rámcem) pro popis dalších jazyků (podobně jako XML). Umožňuje využít jednotným způsobem klasifikačních schémat, tedy souborů vlastností s definovanou sémantikou a omezeními kladenými na možné hodnoty těchto vlastností. Začlenění klasifikačních schémat, které kromě vlastností často obsahují i definici hierarchie tříd a objektů nesoucích dané vlastnosti, do struktury RDF/XML je zajištěno prostřednictvím jmenných prostorů XML. Každá vlastnost použitá v RDF/XML dokumentu musí patřit do nějakého jmenného prostoru a každý jmenný prostor musí mít vlastní jednoznačný identifikátor, tedy URI. URI většinou ukazuje na místo, kde je uloženo tzv. RDF schéma, což je strojově čitelná definice daného klasifikačního schématu implementovaná opět v RDF/XML. Alternativou k RDF schématům jsou novější jazyky pro popis ontologií DAML+OIL a OWL, které jsou sice složitější, zato ale více expresivní.
Fragment XML kódu odpovídající struktuře RDF/XML a uzavřený v elementu rdf:RDF je nazýván RDF popisem (RDF description). Na příkladu konkrétního článku fiktivního zpravodajského serveru sport.cz si ukažme, jak může takový RDF popis vypadat:
<rdf:RDF
xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmlns:vcard="http://www.imc.org/vcard/3.0/"
xmlns:dc="http://purl.org/dc/elements/1.1/">
<rdf:Description about="http://www.sport.cz/fotbal/2003/12/04/spartachelsea.html">
<dc:Title>Sparta – Chelsea 0:1</dc:Title>
<dc:creator rdf:resource = "http://www.sport.cz/authors/PetrMatulik"/>
<dc:date>2003-12-04</dc:date>
</rdf:Description>
<rdf:Description about = "http://www.sport.cz/authors/PetrMatulik">
<vcard:fn>Petr Matulík</vcard:fn>
<vcard:email>petrmatulik@email.cz</vcard:email>
</rdf:Description>
</rdf:RDF>
Na příkladu vidíme, že element rdf:RDF obsahuje deklarace jmenných prostorů, kde první z nich ukazuje na RDF schéma, které definuje základní prvky RDF/XML určující strukturu RDF/XML popisu, a další specifikují klasifikační schémata (RDF schémata), která obsahují definice dále použitých vlastností. Element rdf:Description, který určuje popisovaný zdroj, obsahuje elementy představující vlastnosti daného zdroje. Hodnotou vlastnosti dc:creator popisovaného zdroje je jiný zdroj, který následně rovněž popíšeme prostřednictvím elementu rdf:Description. V tomto RDF/XML popisu jsme tedy popsali dva zdroje (identifikované pomocí URI) a vyjádřili jsme i jejich vzájemný vztah.
RDF/XML popisy HTML zdrojů lze buď přímo vkládat do hlavičky (elementu head) HTML kódu daného zdroje, nebo ukládat do fyzicky samostatných dokumentů a připojovat ke zdroji pomocí elementu link.
Mohlo by se zdát, že i samotné XML dokumenty jsou vhodným prostředkem pro výměnu obecně použitelných metadat, struktura dat XML je však pro zpracování a uchování mnohem náročnější než struktura dat RDF. Na strukturu dat zachycených pomocí RDF lze pohlížet jako na orientovaný ohodnocený graf, což umožňuje využití již dávno známých, ověřených a hlavně efektivních algoritmů pro procházení grafem. Data pak navíc mohou být v relačních databázích uchovávána jako pouhý soubor nezávislých trojic {zdroj, vlastnost, hodnota vlastnosti}, jejichž pořadí nehraje roli. Obě zmíněné výhody mají velký význam pro ideu „Sémantického webu“, která počítá s popisem a následným zpracováním metadat obrovského množství www zdrojů.
Proti rozšíření popisů RDF/XML mluví zejména jeho relativní složitost pro průměrného webmastera, který by měl takový popis tvořit, ale také fakt, že RDF/XML lze psát dvěma různými způsoby, což zvyšuje složitost implementace nástrojů, které by RDF/XML rozuměly. Proto například nelze předpokládat, že by se o parsing RDF/XML dokumentů pokoušeli i laici, jako tomu je u populárního RSS.
I když se RDF zatím výraznějším způsobem při popisu webových zdrojů neprosadilo, existuje již velké množství nástrojů, které si s ním umí poradit. Na programovacím jazyku Java jsou založeny například produkty open-source projektu ICS-FORTH, kde nalezneme například RDF Parser, RDF databázi či definici speciálního dotazovacího jazyka RQL (RDF query language) pro RDF databáze. Další databázi RDF lze naleznout na http://www.guha.com/rdfdb/. Na http://sourceforge.net/projects/rdf-filter/ se nachází javský filtr tvořící rozhraní mezi aplikačním programovým rozhraním SAX a RDF. Populárním nástrojem je také javský balík SIRPAC, který je schopen validovat RDF/XML dokumenty, prezentovat je jako množinu trojic odpovídajícího datového modelu a visualizovat tento model pomocí grafu. Implementace SIRPACu můžeme najít na adrese http://www.w3.org/RDF/Validator/. http://www.w3.org/Library/ přináší demonstrační knihovnu W3C, která obsahuje RDF parser založený na SIRPACu. Projekt Redland na http://www.redland.opensource.ac.uk poskytuje knihovnu, která tvoří aplikační rozhraní pro RDF v mnoha programovacích jazycích (Java, Perl, PHP, Python atd.). Za zmínku stojí také RDF parser implementovaný v Perlu (http://www.gingerall.com/charlie/ga/xml/p_rdf.xml), který dokáže například konvertovat mezi RDF/XML a RDF/N3 (alternativní syntaxe RDF), nebo soubor nástrojů pro XML a RDF na http://www.4suite.org. Zmiňme se také o on-line editoru na http://metadata.net/reg, který přijme zadané RDF schéma a umožní nám zadávat hodnoty jednotlivých vlastností definovaných v daném RDF schématu. Výsledek generuje v RDF/XML i jiných formátech. Na závěr uveďme nástroj RDFPic pro vkládání RDF popisu obrázku přímo do obrázku samotného.
Klasifikačním schématům (dále jen „schémata“) použitým v rámci RDF/XML už jsme se stručně věnovali výše. Schémata (zvaná též profily či ontologie) však nejsou úzce spojena s modelem a syntaxí RDF. Model RDF naopak vznikl za účelem standardizovaného přiřazení jednotlivých vlastností z různých schémat k webovým zdrojům. Vlastnosti z jednotlivých schémat lze v současné době ke zdroji připojit buď prostřednictvím RDF/XML nebo s využitím elementů meta a link HTML dokumentů
Jednotlivá schémata obsahují seznam vlastností, které lze využít v určité specializované oblasti, např. ve zdravotnictví, v oblasti práva a podobně. Pro oblast popisu webových zdrojů se však jako nejvhodnější jeví schéma Dublin Core. Jeho jméno je odvozeno od názvu města Dublin v USA, které je spojeno se vznikem schématu. V dnešní době je Dublin Core jednoznačným leaderem mezi používanými schématy. Po celém světě je využíván knihovnami, muzei, vzdělávacími i vládními organizacemi. I v České republice je plánováno jeho využití při popisu digitálních zdrojů státních organizací a z tohoto důvodu dochází k přizpůsobení standardu českým podmínkám. Oficiální stránky projektu Dublin Core Czech obsahující i český překlad standardu se nachází na http://www.ics.muni.cz/dublin_core/. Dublin Core se skládá z 15 prvků – vlastností, které byly pečlivým procesem pravidelných seminářů vybrány jako základ pro popis webových zdrojů. Jsou jimi název (title), předmět a klíčová slova (subject), popis (description), typ zdroje (type), zdroj (source), vztah (relation), pokrytí (coverage), tvůrce (creator), vydavatel (publisher), přispěvatel (contributor), správa autorských práv (rights), datum (date), formát (format), identifikátor zdroje (identifier) a jazyk (language). Zatímco takzvaný jednoduchý Dublin Core definuje pouze základní význam těchto vlastností, kvalifikovaný Dublin Core umožňuje specifikovat význam přesněji a navíc i určit obor či model hodnot, kterých mohou tyto vlastnosti nabývat. Příklad vyjádření vlastností Dublin Core prostřednictvím RDF/XML jsme si ukázali výše, teď se podívejme, jak je možné Dublin Core vložit přímo do hlavičky HTML dokumentu.
<head profile="http://dublincore.org/documents/dcq-html/"> <title>Vyjádření Dublin Core pomocí HTML/XHTML tagů meta a link</title> <link rel="schema.DC" href="http://purl.org/dc/elements/1.1/" /> <link rel="schema.DCTERMS" href="http://purl.org/dc/terms/" /> <meta name="DC.title" lang="en" content="Vyjádřeni Dublin Core pomocí HTML/XHTML tagů meta a link"/> <meta name="DC.creator" content="Andy Powell, UKOLN, University of Bath" /> <meta name="DCTERMS.issued" scheme="DCTERMS.W3CDTF" content="2003-11-01" /> <meta name="DC.identifier" scheme="DCTERMS.URI" content="http://dublincore.org/documents/dcq-html/" /> <link rel="DCTERMS.replaces" hreflang="en" href="http://dublincore.org/documents/2000/08/15/dcq-html/" /> <meta name="DCTERMS.abstract" content="Tento dokument ukazuje, jak může být Dublin Core kódován pomocí meta tagů /> <meta name="DC.format" scheme="DCTERMS.IMT" content="text/html" /> <meta name="DC.type" scheme="DCTERMS.DCMIType" content="Text" /> </head>
Schéma DC představuje jednoduchý Dublin Core, schéma DCTERMS kvalifikovaný Dublin Core. Vzhledem k důležitosti, jaká se metadatům Dublin Core v rámci budoucího uspořádání "Sémantického webu" připisuje, je pochopitelné, že vzniká velké množství aplikací schopných při tvorbě těchto metadat pomoci. Například Dublin Core Extraction Service je on-line služba, která dokáže ze zadaného xhtml zdroje a na základě zadaného xslt stylu vygenerovat RDF popis obsahující některé vlastnosti slovníku Dublin Core. Podobnou funkcionalitu nabízí zřejmě nejznámější a nejsofistikovanější Dublin Core metadata editor DCdot, který ze zadaného webového zdroje extrahuje (odhadne) některé Dublin Core vlastnosti a umožní je editovat. Následně vygeneruje RDF/XML dokument nebo výstup v některém z mnoha dalších nabízených formátů (např. v HTML, XHTML, SOIF, IMS, LOM, UNIMARC atd.). Českou službu velmi podobného typu nalezneme na http://webarchiv.nkp.cz/cgi-bin/dc_cz.pl, která rovněž umožňuje tvorbu, odhad, čtení a editaci metadat Dublin Core.
Dalším významným schématem je profil vCard, který je určen pro obecný a shodný popis osob a organizací. Vlastnostmi, které poskytuje jsou např. plné jméno (FN), přezdívka (NICNAME), narozeniny (BDAY), funkce (ROLE), adresa (ADR), organizace (ORG), email (EMAIL), tel. číslo (TEL), štítek (LABEL) a poznámka (NOTE). Vlastnosti vCard lze také kvalifikovat z hlediska přesnějšího významu, ale na rozdíl od schématu Dublin Core nejsou ve schématu vCard definovány obory hodnot vlastností prostřednictvím výrazů z řízených slovníků. Fakt, že hodnota vlastnosti TEL představuje tel. číslo do práce lze v RDF/XML zachytit takto:
<rdf:RDF xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmlns:vCard="http://www.w3.org/2001/vcard-rdf/3.0#">
<rdf:Description rdf:about = "http://www.sport.cz/authors/PetrMatulik">
<vCard:TEL rdf:parseType="Resource">
<rdf:value>577988554</rdf:value>
<rdf:type rdf:resource="http://www.w3.org/2001/vcard-rdf/3.0#work"/>
<rdf:type rdf:resource="http://www.w3.org/2001/vcard-rdf/3.0#voice"/>
</vCard:TEL>
</rdf:Description>
</rdf:RDF>
Z příkladu se může zdát, že syntaxe RDF/XML je podstatně složitější než jsme si ukázali výše, ale je to skutečně jen dojem. Bohužel podrobnější rozbor RDF/XML je mimo záběr tohoto článku. Řekněme si jen, že zatímco kvalifikátor work připojený za URI RDF schématu vCard určuje, že číslo uvedené v tagu rdf:value je číslo do práce, kvalifikátor voice nám říká, že jde o číslo telefonní, nikoliv faxové. Oba kvalifikátory jsou definovány přímo ve schématu vCard. Následující krátký fragment RDF/XML ukazuje jak lze vyjádřit fakt, že vlastnost vCard UID (jedinečný identifikátor osoby) představuje rodné číslo v České republice. Toto nelze zajistit pomocí kvalifikátorů vCard.
<vCard:UID vCard:TYPE="RC-CR">8207214136</vCard:UID>
Hodnota atributu vCard:TYPE musí být specifikována v externím dokumentu.
Další schémata si uvedeme jen stručně, a to včetně URI představujících RDF schéma a zároveň jmenný prostor klasifikačního schématu. To z toho důvodu, že pro použití schémat v rámci RDF/XML je tato informace klíčová. Jmenujme si tedy například schémata definovaná konsorciem W3C, konkrétně http://www.w3.org/2000/10/swap/pim/doc# obsahující vlastnosti digitálních dokumentů (verze, nahrazuje, …) a http://www.w3.org/2000/10/swap/pim/contact# s vlastnostmi popisujícími, podobně jako vlastnosti schématu vCard, kontaktní údaje (jméno, mailbox, ...). Dále uveďme schéma http://www.daml.org/2001/03/daml+oil# a jeho vlastnosti týkající se objektů a datových typů ve smyslu objektově orientovaného návrhu. Neměli bychom opomenout ani klasifikační schémata konsorcia PRISM, které se zabývá standardizací metadat v oblasti publikace a výměny obsahu ve zpravodajství. Jmenujme například schémata http://prismstandard.org/namespaces/basic/1.0/ (publikace, licensování a znovupoužití obsahu) a http://prismstandard.org/namespaces/prl/1.0/ (práva digitálních dokumentů). A na závěr se zmiňme o schématech definovaných v rámci pracovního návrhu (working draft) W3C XPackage. Jsou jimi http://xpackage.org/namespaces/2003/file# (popis digitálních souborů ), http://xpackage.org/namespaces/2003/mime# (MIME informace), http://xpackage.org/namespaces/2003/unicode# (použití znaků) a http://xpackage.org/namespaces/2003/xml# (popis xml zdrojů). V prostředí Internetu se začínají objevovat i registry (seznamy) klasifikačních schémat. Můžeme je nalézt např. na http://metadata.net/, http://www.schemas-forum.org/ či http://desire.ukoln.ac.uk/registry/. Registr RDF Schémat vytvořených organizací FORTH nalezneme na http://athena.ics.forth.gr:9090/RDF/Examples.html.
Řízeným slovníkem či tezaurem rozumíme soubor předmětových hesel s definovanou strukturou nadřazených a podřazených termínů a určením synonym. Přestože řízený slovník si může pro vlastní potřebu definovat úzká skupina uživatelů, pro využití v zájmu „Sémantického webu“ je třeba, aby byl slovník dostupný všeobecně. V kontextu RDF je význam řízených slovníků zřejmý. Pro určení hodnoty určité vlastnosti mohou klasifikační schémata vyžadovat použití hesla z konkrétního slovníku, což podstatným způsobem přispívá k interoperabilitě metadat. Toho také mohou využít tvorbu metadat usnadňující aplikace, které jsou kompatibilní s daným schématem a daným slovníkem a které tak mohou průběžně nabízet hesla ze slovníku jako možné hodnoty vlastností. Řízené slovníky jsou používány jako obor hodnot i pro některé vlastnosti klasifikačního schématu Dublin Core. V prostředí kvalifikovaného Dublin Core patří řízené slovníky mezi tzv. kvalifikátory hodnoty, které různými způsoby omezují obor hodnot dané vlastnosti. V podstatě lze při RDF popisu nejen specifikovat hodnoty vybraných vlastností schématu Dublin Core, ale i určit řízený slovník, ze kterého jsme hodnotu vlastnosti vybrali. Vidět to můžeme na následujícím příkladu, který znázorňuje použití řízeného slovníku v rámci kvalifikovaného DC v hlavičce HTML dokumentu.
<meta name= "DC.Subject" scheme= "LCSH" content= "Dublin Core; DC; RDF; XML">
Použití řízeného slovníku LCSH (Library of Congress Subject Headings) je dáno jeho uvedením v atributu scheme. Atribut content pak obsahuje hesla z tohoto slovníku vybraná. Další informace o řízených slovnících včetně jejich dostupnosti na webu lze najít např. v dokumentu na http://info.sks.cz/users/ku/MTI/sjazyky.htm nebo na webových stránkách české verze Dublin Core (viz výše).
V dnešní době asi nejrozšířenějším metadatovým formátem v prostředí Internetu je standard RSS, který však s ideou "Sémantického webu" souvisí jen nepřímo. Na úvod bychom si měli standard představit a říci si, co se pod tímto akronymem skrývá. To však není snadné. Důsledkem neschopnosti vývojářů RSS shodnout se na společném postupu při návrhu specifikace RSS je nejen příslovečné zmatení jazyků, tedy existence více navzájem nekompatibilních verzí, ale i nejednoznačnost v interpretaci významu těchto tří písmen. Proto nejdříve naznačme, k čemu vlastně tento standard slouží.
Na internetu se často dočteme, že RSS je univerzální široce použitelný metadatový formát pro agregaci a syndikaci internetového obsahu. Syndikace je pak ve specifikaci jedné z verzí RSS definována jako vytváření on-line přístupných dat, která slouží k dalšímu přenosu, agregaci a následnému znovupublikování. Definice je to stručná, ale málo kdo má po jejím přečtení v celé věci jasno. Proto to zkusme jinak.
Mnozí z uživatelů internetu jsou zvyklí se prostřednictvím sítě www informovat o novinkách v oblasti, která je zajímá. Proto pravidelně prochází internetové informační zdroje, které se této oblasti týkají, což je samozřejmě časově náročné. Proto přichází RSS, aby zprostředkovalo aktuální informace ze všech námi vybraných zdrojů na jednom místě. To je pochopitelně jen příklad využití RSS, ale jde o využití velmi rozšířené.
K zprostředkování výše zmíněných informací využívá RSS takzvaný exportní soubor (kanál), který odpovídá syntaxi standardu RSS dané verze. Jednou z mála společných vlastností všech verzí RSS je fakt, že všechny jsou aplikací XML, z čehož vyplývá možnost procházet a zpracovat každý exportní soubor (pokud je syntakticky správný) pomocí běžných XML parserů. Soubor se nazývá exportním proto, že umožňuje export výtahu z nových informací, které se objeví na daném webu, a to ve formě stručné a srozumitelné lidem i počítačům. Většinou jde o názvy a stručné popisy obsahu aktuálních článků na zpravodajském serveru, další využití je však prakticky neomezené. Exportní soubor může být buď dynamicky generován, nebo ručně vytvářen webmasterem daného zdroje. Doporučovanými příponami jsou xml, rss nebo rdf. Soubor je zveřejněn (má vlastní URL) a na jeho přístupnost by mělo být adekvátně upozorněno, nejlépe na titulní straně daného webu. Vhodná je také registrace do významných webových agregačních portálů. Soubor se skládá z popisu daného webu a jednotlivých položek, které reprezentují popis nových informací včetně odkazu na jejich zdroj. Takto lze například (s využitím některých níže popsaných nástrojů) dosáhnout toho, že budeme schopni vidět seznam všech nových článků týkajících se oblasti našeho zájmu v jednom okně internetového prohlížeče, a snadno se prostřednictvím odkazu dostat k originálu článku, který si zvolíme.
Naznačili jsme, že vývoj specifikace RSS byl spletitý a jednotlivé verze na sebe nenavazují. Pojďme se tedy na historii standardu podívat trochu podrobněji. Formát RSS vznikl „v dílně“ firmy Netscape, která jej chtěla využít jako mechanismus pro výtah obsahu na svém portálu my.netscape.com. V březnu roku 1999 tedy spatřila světlo internetového světa specifikace RSS 0.9, jejíž jádro bylo založeno na RDF. Později došlo k zjednodušení standardu, odstranění RDF syntaxe a zařazení nových prvků (vlastností) používaných v konkurenčním formátu scriptingNews firmy UserLand. Tak vznikla verze RSS 0.91, která se dodnes hojně používá a jejíž jednoduchost podle mého názoru způsobila pozdější značné rozšíření RSS. Netscape mezitím ztrácí o RSS zájem a hlavní slovo při vývoji standardu získává David Winer z firmy UserLand. Podle mnohých jde o nekonvenčního a impulsivního člověka, s kterým není snadné se domluvit a který je příčinou dnešního chaosu na poli RSS. V dalším období dospívají někteří uživatelé RSS k názoru, že struktura RSS 0.91 je nerozšiřitelná, její použití má příliš úzký obzor a použitá XML syntaxe je spíše intuitivní než přesně definovaná. Proto vzniká samostatná mezinárodní skupina vývojářů, která v prosinci 2000 navrhuje RSS 1.0 založenou na RDF a rozšiřitelnosti (modularizaci) pomocí jmenných prostorů. UserLand reaguje rozšířením své verze na RSS 0.92, později RSS 0.93 a 0.94. U těchto verzí jde v podstatě jen o přidávání nových prvků. Na požadavek rozšiřitelnosti odpovídá až v srpnu 2002, kdy publikuje verzi 2.0 používající jmenné prostory.
Teď už můžeme objasnit význam akronymu RSS pro jednotlivé verze standardu. RSS 0.9x představovalo zkratku pro Rich Site Summary. Verze 1.0 vykládá RSS jako RDF Site Summary a korunu těmto zmatkům nasazuje Dave Winer a jeho RSS 2.0 s významem Really Simple Syndication.
V dnešní době už byste nalezli jen málo zpravodajských serverů a významnějších weblogů, které nepoužívají RSS. Využití tří nejoblíbenějších verzí, tedy 0.91, 1.0 a 2.0 je však poměrně vyrovnané, což klade zvýšené nároky na tvůrce nástrojů pro zpracování RSS. Posuďte sami. Následující graf zachycuje poměr využití jednotlivých verzí RSS v exportních souborech sdružovaných na portálu Syndic8, který je zřejmě nejobsáhlejším zdrojem pro každého, kdo by se chtěl o RSS zajímat podrobněji. Jde o Web věnující se oblasti sdružování zpravodajských kanálů. Kromě základních informací o používaných formátech zde lze najít velké množství odkazů na weby a projekty věnované této problematice. Z množství uživatelů jednotlivých verzí je zřejmé, že jde o vzorek opravdu reprezentativní.
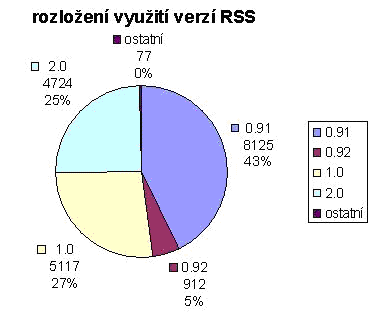
Pro ilustraci uveďme příklady nejpoužívanějších verzí RSS, a to na již dříve použitém příkladu zpravodajského serveru sport.cz, který pomocí RSS upozorňuje na nové články. Z důvodu úspory místa použijeme v exportním souboru jen 2 položky. Jejich množství je obecně neomezené, běžnou praxí je však 10 až 15 položek na 1 exportní soubor. U všech tří souborů chybí definice použitého DTD (Document Type Definition), přestože se objevit může. Byla povinná pouze u prvních verzí produkovaných firmou Netscape. Po prostudování struktury RSS exportního souboru je jasné, že může sloužit k agregaci jakýchkoli diskrétních jednotek informace, tedy například autorů a jejich e-mailových adres na daném webu, informací o produktech dané firmy, informací o zboží nabízeném daným elektronickým obchodem, sportovních výsledků, atd.
RSS 0.91 má povinný kořenový element rss, který používá rovněž povinný atribut version pro udání verze RSS. Následuje element channel, obsahující svůj vlastní popis a jednotlivé položky.
<?xml version=”1.0”?>
<rss version="0.91">
<channel>
<title>sport.cz</title>
<link>http://www.sport.cz/</link>
<description>sport.cz poskytuje široké spektrum informací ze všech sportovních odvětví</description>
<language>cs</language>
<item>
<title>Sparta – Chelsea 0:1</title>
<link>http://www.sport.cz/fotbal/2003/12/04/spartachelsea.html</link>
<description>V tomto článku se zaměříme na průběh zápasu Sparta – Chelsea, na rozbor obranné hry pražského týmu a jeho perspektivy v dalším průběhu Ligy mistrů</description>
</item>
<item>
<title>Zlín Hood 2003 – turnaj v lukostřelbě</title>
<link>http://www.sport.cz/ostatni/2003/12/04/zlinhood.html</link>
<description>Extrémně zajímavé klání našich předních lukostřelců se odehrálo ve městě obuvi. Vzrušující atmosféru jsme se snažili zprostředkovat v tomto článku</description>
</item>
</channel>
</rss>
Exportní soubor RSS 1.0 je poněkud méně čitelný pro běžného uživatele a jeho kód je trochu rozsáhlejší než u RSS 0.91, zároveň však poskytuje snadnou rozšiřitelnost pomocí jmenných prostorů definovaných v kořenovém elementu rdf:RDF. Použití předpony rdf pro implicitní jmenný prostor RDF je povinné, ostatní předpony jsou volitelné.
<?xml version=”1.0”?>
<rdf:RDF
xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmlns="http://purl.org/rss/1.0/"
xmlns:dc="http://purl.org/dc/elements/1.1/"
>
<channel rdf:about="http://www.sport.cz/xml/rss.xml">
<title>sport.cz</title>
<link>http://www.sport.cz/</link>
<description>sport.cz poskytuje široké spektrum informací ze všech sportovních odvětví</description>
<language>cs</language>
<items>
<rdf:Seq>
<rdf:li rdf:resource="http://www.sport.cz/fotbal/2003/12/04/spartachelsea.html"/>
<rdf:li rdf:resource="http://www.sport.cz/ostatni/2003/12/04/zlinhood.html"/>
</rdf:Seq>
</items>
</channel>
<item rdf:about="http://www.sport.cz/fotbal/2003/12/04/spartachelsea.html">
<title>Sparta – Chelsea 0:1</title>
<link>http://www.sport.cz/fotbal/2003/12/04/spartachelsea.html</link>
<description>V tomto článku se zaměříme na průběh zápasu Sparta – Chelsea, na rozbor obranné hry pražského týmu a jeho perspektivy v dalším průběhu Ligy mistrů.</description>
<dc:creator>Petr Matulík</dc:creator>
<dc:date>2003-12-04</dc:date>
</item>
<item rdf:about="http://www.sport.cz/ostatni/2003/12/04/zlinhood.html">
<title>Zlín Hood 2003 – turnaj v lukostřelbě</title>
<link>http://www.sport.cz/ostatni/2003/12/04/zlinhood.html</link>
<description>Extrémně zajímavé klání našich předních lukostřelců se odehrálo ve městě obuvi. Vzrušující atmosféru jsme se snažili zprostředkovat v tomto článku</description>
<dc:creator>Priya Lakshminarayanan</dc:creator>
<dc:date>2003-12-04</dc:date>
</item>
</rdf:RDF>
RSS 2.0 rovněž umožňuje rozšiřitelnost pomocí jmenných prostorů, uvedených v kořenovém elementu. Je také zpětně kompatibilní s předchozími verzemi 0.9x, což je umožněno faktem, že nástroje pro zpracování RSS ignorují elementy, které neznají.
<?xml version=”1.0”?>
<rss version="2.0" xmlns:dc="http://purl.org/dc/elements/1.1/">
<channel>
<title>sport.cz</title>
<link>http://www.sport.cz/</link>
<description>sport.cz poskytuje široké spektrum informací ze všech sportovních odvětví</description>
<language>cs</language>
<item>
<title>Sparta – Chelsea 0:1</title>
<link>http://www.sport.cz/fotbal/2003/12/04/spartachelsea.html</link>
<description>V tomto článku se zaměříme na průběh zápasu Sparta – Chelsea, na rozbor obranné hry pražského týmu a jeho perspektivy v dalším průběhu ligy mistrů.</description>
<dc:creator>Petr Matulík</dc:creator>
<dc:date>2003-12-04</dc:date>
</item>
<item>
<title>The .NET Schema Object Model</title>
<link>http://www.sport.cz/ostatni/2003/12/04/zlinhood.html</link>
<description>Extrémně zajímavé klání našich předních lukostřelců se odehrálo ve městě obuvi. Vzrušující atmosféru jsme se snažili zprostředkovat v tomto článku.</description>
<dc:creator>Priya Lakshminarayanan</dc:creator>
<dc:date>2003-12-04</dc:date>
</item>
</channel>
</rss>
Udělejme si nyní přehled o nástrojích, které jsou určeny ke zpracování a využití standardu RSS. Zmíníme se o aplikacích, které jsou na internetu volně dostupné.
Nejčastěji používaným nástrojem jsou takzvané desktopové čtečky (neboli agregátory) RSS. Jde o aplikace klasicky instalované na počítač uživatele, do kterých lze zaregistrovat jednotlivé exportní soubory námi vybraných internetových zdrojů (webů). Čtečka pak periodicky stahuje všechny zaregistrované exportní soubory a jejich obsah prezentuje vhodným způsobem uživateli. Vzniká tak dojem, že data nejsou stahována uživatelem, ale spíše tlačena webovými zdroji k uživateli. Mluvíme o takzvaném push-efektu. Jednou z používaných funkcí „desktopových“ čteček je upozornění na novou informaci (například právě publikovaný článek) na jakémkoliv zaregistrovaném zdroji. Uživatel tak může okamžitě pomocí odkazu prezentovaného čtečkou přejít na původní zdroj informace. Uživatel také nemusí procházet všechny zdroje, které poskytují informace v oblasti, která ho zajímá, ale stačí mu pouze přečíst si popisy jednotlivých nových informací (řekněme výtahy z článků) a vybrat si přesně to téma, které ho právě zaujme. K nejrozšířenějším čtečkám patří FeedDemon, FeedReader a ActiveRefresh pro operační systémy Windows a například Shrook pro MacOS X. Existují také čtečky ve formě plug-inu pro existující aplikace, například RSS Miranda Plugin pro Instant Messenger Miranda, Newsgator běžící pod Microsoft Outlook nebo panel nástrojů (takzvaný „sidebar“) do prohlížeče Mozilla(http://www.theonering.net/staff/corvar/cgi-bin/sidebar-inst.pl. Dnes už je jasné, že panel nástrojů RSS bude i přímo v základní výbavě nového operačního systému Windows Longhorn.
Ne každý ovšem má důvěru k freewarovým aplikacím stahovaným z internetu a raději dá přednost RSS agregátorům ve formě webové služby. Jde v podstatě o webové aplikace, které sami sdružují informace z exportních souborů a on-line je publikují na svých webových stránkách. Uživatel se obvykle může registrovat k používání personifikovaného agregátoru a vytvářet vlastní seznam sledovaných exportních souborů. V zahraničí je nejvýznamnějším hráčem na tomto poli portál Moreover. Naopak v českém prostředí jsou nejznámějšími agregátory tohoto typu zejména všeobecně zaměřené portály Právě dnes a rss.pooh.cz. Přehled obsahu českých weblogů poskytuje portál RSSky a na oblast hardware a software je zaměřem Minasite. Tyto on-line agregátory často akceptují i jiné formáty pro agregaci obsahu. Na takových je pak třeba se s webmasterem daného webu dohodnout.
Využít RSS však může průměrný webmaster nejen pro publikaci agregovaného obsahu vlastního webu, ale i pro začlenění obsahu cizího exportu na své stránky. K tomu musí na svém webu implementovat parsing RSS exportních souborů, což není zrovna triviální záležitost. Pomoci mu mohou služby poskytované např. na http://jade.mcli.dist.maricopa.edu/feed/, kde stačí zadat URL exportního souboru, který chce zahrnout do svých stránek, a po odeslání je mu vygenerován krátký kód v javascriptu, který jednoduše vloží do svého kódu. Problémy ovšem vznikají při kódování českých znaků. Bezchybně funguje jen pro RSS kódované v UTF-8. Na adrese http://feedvalidator.org lze ověřit syntaktickou správnost zvoleného exportního souboru. Existují i služby, které po zadání URL validního XHTML zdroje vygenerují jeho reprezentaci v RSS 1.0 (například na http://www.ilrt.bris.ac.uk/discovery/2000/08/hss/sw.html). Další zajímavou službou může být RSS agregátor Novobot, který má nejen klasické vlastnosti, ale dokáže také procházet zdroje na zadaných URL a generovat jejich hlavičky (s využitím nadpisů, odkazů atd.) i bez existence exportních souborů.
Obrovská síla standardu RSS je v jeho jednoduchosti. Formát, který nelze pochopit prakticky okamžitě a který tak nemůže průměrný webmaster okamžitě začít používat, nemá šanci se v prostředí Internetu masově prosadit. RSS však tuto vlastnost má, a to mu spolu s širokou použitelností a faktem, že je založen na XML, prožívajícím obrovský rozmach, zaručuje zvýraznění již tak značného náskoku v rozšíření před ostatními metadatovými standardy.
S problematikou syndikace a agregace internetového obsahu souvisí i formát OCS (Open Content Syndication). Jeho cílem je poskytnout jednotný a strojově čitelný seznam zpravodajských kanálů pro dané webové sídlo. Například zpravodajský portál může být vybaven velkým množstvím takových kanálů. Ty se od sebe mohou lišit obsahem, formátem, verzí formátu, úplností, frekvencí aktualizace apod. Dokument ve formátu OCS je zachytí, jeho umístění je vhodným způsobem zveřejněno a informace v něm obsažené lze využít pro automatické nalezení a případné zpracování všech zpravodajských kanálů daného portálu.
Pěkným a zdá se, že i poměrně stabilizovaným formátem pro zveřejnění metadat webových stránek je formát XFML (eXchangeable Faceted Metadata Language), který částečně vychází ze specifikace Topic Maps. Pomocí XFML lze vytvořit vlastní témata (topics, facets), jejichž strukturu lze uložit do veřejně přístupného xml dokumentu - tématické mapy (topic map). Ve stejném dokumentu se specifikuje, které URI našeho webu patří do kterého tématu. Jednotlivé tématické mapy lze propojovat pomocí určení ekvivalence (shodnosti) mezi tématem z jedné mapy a tématem z druhé. Takto vzniká struktura tématicky a hlavně ručně zařazených URI, podobná katalogizačním službám typu Yahoo. Tato struktura však může být nesrovnatelně rozsáhlejší. V dnešní době existuje několik XFML kompatibilních aplikací. Uveďme si příklad tématické mapy XFML.
<?xml version="1.0"?> <xfml version="1.0" url="http://xfml.org/spec/example.xml" language="en-us"> <!-- MAPINFO --> <mapInfo> <managingEditor> <name>Peter Van Dijck</name> </managingEditor> <generator> <name>Hand written document</name> </generator> </mapInfo> <!-- FACETS --> <facet id="place_to_go">places to go</facet> <facet id="author">author</facet> <facet id="thing_to_do">things to do</facet> <!-- TOPICS --> <topic id="colombia" facetid="place_to_go"> <name>Colombia</name> <connect>http://othersite.com/xfml.xml#18753</connect> <psi>http://www.cia.gov/cia/publications/factbook/geos/co.html</psi> <psi>http://poorbuthappy.com/colombia</psi> <description>Colombia, the country</description> </topic> <topic id="diving" facetid="thing_to_do"> <name>diving</name> </topic> <!-- PAGES --> <page url="http://poorbuthappy.com/colombia"> <title>Guide to Colombia</title> <description>A website about Colombia</description> <occurrence topicid="diving"/> <occurrence topicid="colombia" strength="5"/> </page> <page url="http://poorbuthappy.com/colombia/topics.php"> <title>Guide to Colombia topics page</title> <occurrence topicid="diving"/> <occurrence topicid="colombia"/> </page> </xfml>
V elementu mapinfo se nacházejí metainformace o samotném dokumentu. Dále následuje definice jednotlivých faset (facet), do kterých budou zařazeny dále definované kategorie (topic). Fasety jsou vlastně kategorie nejvyšší úrovně. Kategorie jsou popsány v následující části včetně odkazů na zdroje, které určují sémantiku dané kategorie, a odkazů na ekvivalentní kategorie v jiných dokumentech XFML. Na závěr je definováno zařazení jednotlivých námi popisovaných URI do kategorií.
Dovolte mi, abych na závěr trochu odbočil od tématu "Sémantického webu". V poslední době se do popředí zájmu na mnoha vysokoškolských zařízeních dostává možnost zapojení znalostí a pokroku na poli informatiky do služeb vzdělávání. Problém elektronického vzdělávání (tzv. e-learningu) na MU byl komplexně probrán v článcích Tomáše Pitnera a Jiřího Rambouska v rámci tohoto zpravodaje, takže na nás teď je, abychom se trochu podrobněji podívali na metadata podporující e-learning.
V roce 1997 začali členové projektu IMS (Instructional Management Systems) organizace EDUCOM (dnes EDUCAUSE), konsorcia institucí vysokoškolského vzdělávání v USA, pracovat na otevřeném standardu pro on-line výuku včetně specifikace metadat výukového obsahu. V tomtéž roce se stejným směrem vydali i organizace NIST (National Institute for Standards and Technology) a IEEE LTSC (IEEE Learning Technology Standards Commitee). NIST a IMS spojili své síly a začali spolupracovat s evropským projektem pro e-learningová metadata ARIADNE (Alliance of Remote Instructional Authoring and Distribution Networks for Europe), který vznikl už v polovině 90. let. V roce 1998 přihlašují IMS a ARIADNE společný návrh metadat standardizační organizaci IEEE, jejíž schvalovací a pozměňovací proces dospěl v roce 2002 k „závěrečnému návrhu“ IEEE Learning Object Meta-Data (LOM) Final Draft. V roce 1998 také Ministerstvo obrany Spojených států zakládá iniciativu ADL (Advanced Distributed Learning), aby určila strategii využití dostupných vzdělávacích a informačních technologií pro efektivní výuku a trénink. Výsledkem je model SCORM (Sharable Content Object Reference Model) představující produkt snahy o koordinaci a spojení technologií, implementací a specifikací mnoha organizací, včetně IEEE a IMS. Také ustavení komise pro výuku a vzdělávání v rámci nejvýznamnější standardizační organizace ISO je dotvrzením narůstajícího zájmu o elektronické vzdělávání.
Klíčovým pojmem pro všechny standardy v oblasti e-learningu je tzv. výukový objekt (learning object či learning resource, v dalším textu se přidržíme anglické zkratky LO). IEEE LTSC definuje LO jako jakoukoliv entitu, digitální i nedigitální, která může být použita či odkazována v rámci technologie podporující výuku. Příkladem takové technologie může být počítačový tréninkový systém, interaktivní výukové prostředí, inteligentní počítačový instruktážní systém nebo systém pro podporu distančního vzdělávání. Mezi příklady LO spadá jakýkoliv multimediální obsah, cíle výuky, výukový software či osoby, organizace a události odkazované v rámci technologie podporující výuku. Metadata jsou pro e-learning důležitá z toho důvodu, že jejich prostřednictvím lze dosáhnout mnoha cílů klíčových pro vizi univerzálních, sdílitelných, znovu použitelných částí výukových systémů. Tyto části bude možno použít pro sestavení výukových procesů pro každého uživatele zvlášť. To v jednom ze svých důsledků znamená, že každému studentu bude podle jeho individuálních charakteristik a zájmů sestaven jedinečný vzdělávací postup, který mu bude tzv. „šitý na míru“. Takovými částmi jsou právě LO. Metadata se dosažení těchto cílů účastní zejména tím, že umožňují vyhledání, vyhodnocení, získání, použití, sdílení a výměnu LO a podporují nezbytnou bezpečnost a autentizaci, které jsou potřebné pro distribuci a použití LO. Důsledkem použití metadat by pak měl být vznik elektronického trhu LO, který by poskytoval LO zdarma i výdělečně.
Rozhodující roli na poli e-learningových metadat hraje standard LOM, o jehož původu jsme se zmínili výše. Specifikuje syntaxi a sémantiku metadat LO. Jádrem standardu je konceptuální datový model, který definuje strukturu metadatové instance (metadatového popisu) pro daný LO. Metadatová instance popisuje vlastnosti daného LO, které mají předepsanou hierarchickou strukturu, velmi podobnou struktuře elementů v XML Na nejvyšší úrovni hierarchie se nacházejí kategorie, které seskupují vlastnosti daného LO tématicky. Standard LOM tyto kategorie popisuje následovně:
a) Kategorie Obecné (General) seskupuje obecné informace popisující LO jako celek.
b) Kategorie Životní cyklus (Lifecycle) seskupuje informace týkající se historie a aktuálního stavu LO a informace o vlivech na LO během jeho vývoje.
c) Kategorie Meta-Metadata seskupuje informace o metadatové instanci samotné (nikoliv o LO, kterého se tato instance týká)
d) Kategorie Technické (Technical) seskupuje technické požadavky na daný LO a technické charakteristiky daného LO.
e) Kategorie Vzdělávací (Educational) seskupuje charakteristiky LO, které se týkají vzdělávání a pedagogiky.
f) Kategorie Práva (Rights) seskupuje vlastnosti týkající se intelektuálních práv a podmínek použití LO.
g) Kategorie Vztah (Relation) seskupuje vlastnosti definující vztahy mezi daným LO a jinými LO.
h) Kategorie Anotace (Annotation) poskytuje komentáře k využití LO v rámci výuky a také informace o tom, kdo a kdy tyto komentáře vytvořil.
i) Kategorie Klasifikace (Classification) popisuje LO ve vztahu ke konkrétnímu klasifikačnímu systému.
Vlastnosti jsou v těchto kategoriích seskupeny jako datové elementy, které se dělí na agregační elementy (uzly hierarchie) a jednoduché elementy (listy hierarchie). Pouze jednoduché elementy mohou mít konkrétní textovou hodnotu, agregační elementy obsahují pouze další elementy. Pokud bychom se vrátili k terminologii běžné v rámci „Sémantického webu“ a zejména RDF, zdrojem by byl popisovaný LO, vlastnost by byla určena cestou z nejvyšší úrovně hierarchie LOM do některého listu hierarchie a hodnotou vlastnosti by byla právě hodnota onoho listu. Použijeme-li tečkové notace, která je v rámci specifikace LOM běžná, příkladem vlastnosti může být cesta Relation.Resource.Description, která se dá slovně vyjádřit jako „popis zdroje, který je ve vztahu s popisovaným LO“, a hodnotou této vlastnosti by pak byla hodnota jednoduchého elementu Description. LOM pro každý datový element definuje jméno, vysvětlení (definici), povolený počet hodnot, uspořádanost či neuspořádanost hodnot a ilustrativní příklad, pro jednoduché elementy ještě navíc definuje datový typ a obor hodnot. Všechny datové elementy jsou volitelné, pro použití libovolného listového elementu je však pochopitelně nutné použít i všechny jeho rodiče (tedy nadřazené uzlové elementy). Pro určení oboru hodnot jsou často využívány řízené slovníky, které pak určují doporučené hodnoty pro daný listový element. Zajímavou skutečností je, že sémantika libovolné hodnoty vybrané z libovolného slovníku je definována prostřednictvím odpovídajícího termínu v Oxford English Dictionary, 2nd Ed., 1989, což internacionalizaci standardu příliš nenahrává.
Ve zpracování organizace IEEE jsou už i standardy pro aplikaci LOM jako XML či RDF. Pro ilustraci si také ukažme, jak by takový XML LOM dokument mohl vypadat. Poznamenejme jen, že popisovaným LO je dokument ve formátu pro MS Word.
<lom xmlns="http://ltsc.ieee.org/xsd/LOMv1p0">
<general>
<title>
<langstring xml:lang="en">Draft Standard for Learning Object Metadata</langstring>
<langstring xml:lang="cs">Návrh standardu pro metadata výukových objektů</langstring>
</title>
<language>en</language>
<description>
<langstring xml:lang="en">Metadata is information about …</langstring>
<langstring xml:lang="cs">Metadata jsou informace o …</langstring>
</description>
<keyword>
<langstring xml:lang="en">metadata</langstring>
<langstring xml:lang="cs">metadata</langstring>
</keyword>
<keyword>
<langstring xml:lang="en">learning object</langstring>
<langstring xml:lang="cs">výukové objekty</langstring>
</keyword>
</general>
<lifecycle>
<version>
<langstring xml:lang="x-none">1.0</langstring>
</version>
<status>
<source>
<langstring xml:lang="x-none">LOMv1.0</langstring>
</source>
<value>
<langstring xml:lang="x-none">Draft</langstring>
</value>
</status>
</lifecycle>
<metametadata>
<metadatascheme>LOMv1.0</metadatascheme>
<metadatascheme>ARIADNEv3</metadatascheme>
</metametadata>
<technical>
<format>application/msword</format>
<size>210000</size>
<location type="URI">http://ltsc.ieee.org/wg12/exactreference.doc</location>
</technical>
<educational>
<typicalagerange>
<langstring xml:lang="x-none">18-</langstring>
</typicalagerange>
<typicallearningtime>
<datetime>PT3H</datetime>
</typicallearningtime>
</educational>
</lom>
Všechny další specifikace metadat pro elektronické vzdělávání jsou v podstatě jen aplikací LOM, tzn. že obsahují jistá rozšíření, zúžení, případně zpřesnění oproti čístému LOM. Patří mezi ně například Doporučení pro metadata verze 3.2 projektu ARIADNE či Specifikace IMS pro metadata verze 1.1, která obsahuje jak datový model a široký seznam řízených slovníků vhodných pro použití při určení hodnoty toho kterého listového datového elementu LOM, tak i vyjádření LOM v XML a RDF. Za příklad konkrétního zapojení standardu LOM do služeb e-learningové komunity a přizpůsobení tohoto standardu lokálním podmínkám může sloužit tzv. UK LOM core, tedy aplikace LOM v prostředí britského e-learningu. Za zmínku stojí také specifikace VDEX (Vocabulary Definition Exchange) projektu IMS pro unifikaci formátu řízených slovníků a pozornosti by neměl uniknout ani EdNA Metadata Standard verze 1.1 australské národní iniciativy EdNA (Education Network Australia), která tvoří australský národní rámec pro spolupráci při používání Internetu za účelem vzdělávání a tréninku. Tento standard je však založen spíše na využití a rozšíření klasifikačního schématu Dublin Core. Generovat metadata ve formátu LOM či IMS LOM lze pomocí výše zmíněného on-line metadata generátoru DCdot.
Vrátíme-li se nyní k vizi „Sémantického webu“, je třeba zdůraznit, že existuje i několik problémů, které s touto vizí souvisí. Problémem je například fakt, že odpovědnost za syntaktickou správnost a sémantickou korektnost metadat padá na hlavu samotného tvůrce popisovaného zdroje. To s sebou samozřejmě přináší riziko podvodů nebo omylů ze strany tvůrců. Proto se zdá, že nejdříve je třeba vytvořit jednoduchý a srozumitelný standard pro zajištění důvěryhodnosti webu a takový tady zatím není. Dalším problémem je nejasná budoucnost URI, který už brzy pro identifikaci obrovského množství informací nebude stačit. Nejednoznačnosti v oblasti jednoznačné identifikace webových zdrojů mohou přinést mnoho problémů. V budoucnu by standard URI měli nahradit vyvíjející se standardy DOI či URN. Mnoho internetových tvůrců se také ptá, proč pracně popisovat své zdroje prostřednictvím metadat, když neexistují nástroje, které by potenciál těchto metadat dokázaly využít. Příklad dnes populárního RSS však ukazuje, že vznik velkého množství kvalitních nástrojů teprve následuje rozšíření výskytu metadat. Chceme-li tedy, aby se služba www sítě Internet stala přehlednou a důvěryhodnou knihovnou s neomezeným množstvím informací a nahradila tak stávající změť těžko rozlišitelných a často „neviditelných“ zdrojů, musíme dosáhnout začlenění co nejširšího spektra metadat do její struktury.