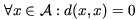
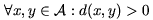
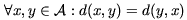
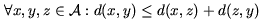
The search operation has traditionally been applied to structured (attribute-type) data. Complex data types - such as images, videos, time series, text documents, DNA sequences, etc. - are becoming increasingly important in a variety of modern applications (for instance digital libraries). Searching in such data requires a gradual rather than the exact relevance, so it is called the similarity retrieval. This process involves finding all objects in the database that are similar to a given query object. It has become customary to assume the similarity measure as a distance metric. The primary challenge in performing similarity search is to structure the database in such a way so that the search can be performed fast.
Though many metric index structures have been proposed, most of them are only main memory structures and thus not suitable for a large volume of data. The scalability of disk oriented metric indexes have also been studied and the results demonstrate significant speed-up (both in terms of distance computations and disk-page reads) in comparison with the sequential search. Unfortunately, the search costs are also linearly increasing with the size of the data-set.
Therefore the objectives of my research is to use the scaleable distributed techniques so that the metric data structure would scale up with nearly constant search time. In this respect, my contribution can be seen as a Scalable and Distributed Data Structure (SDDS), which uses the P2P paradigm for the communication in a Grid-like computing infrastructure.
The mathematical metric space is a pair (A,d), where A is the domain of objects and d is the distance function able to compute distances between any pair of objects from A. It is assumed that the smaller the distance, the closer or more similar the objects are. The distance function must satisfy following properties:
| reflexivity | |
|---|---|
| strict positiveness | |
| symmetry | |
| triangle inequality | |
Every SDDS should meet following constraints:
| scalability | data expand to new servers gracefully, and only when servers already used are efficiently loaded |
|---|---|
| no hot-spot | there is no master site that object address computations must go through, e.g., to access a centralized directory |
| independence | The file access and maintenance primitives, e.g., search, insertion, split, etc., never require atomic updates to multiple clients. |
We can define peer to peer (P2P) systems as distributed systems without any centralized control or hierarchical organization, where the software running at each node is equivalent in functionality. Data in the system are distributed among the participating nodes. Every node joined in P2P both hold data and perform queries.
P2P systems are popular because of the many benefits they offer: adaptation, self-organization, load-balancing, fault-tolerance, availability through massive replication, and the ability to pool together and harness large amounts of resources. For example, file-sharing P2P systems distribute the main cost of sharing data, i.e. bandwidth and storage, across all the peers in the network, thereby allowing them to scale without the need for powerful and expensive servers.
| Scalability | the structure should scale gracefully through utilizing new nodes of the distributed environment. The data should be distributed evenly between all active nodes. The search time should remain (nearly) constant for performed queries - the query could utilize more distributed nodes in order to retrieve results. |
|---|---|
| Extensibility | the structure should be able to search different types of objects. It should support primary key search with exact or range match, vector spaces with any dimension or even more complicated sets of objects, which only supports some similarity measurement. All those mentioned methods are easily transformed to a generic metric space with appropriate distance function. |
| Similarity queries | at least the two basic types of similarity searches (range and nearest neighbors queries) should be supported by the structure. |
| Huge objects | there should be support for large objects (megabytes of size). This requirement is needed for the multimedia files (for example pictures), because they can be stored using metric space techniques and the structure should be able to deal with them. |
The proposed algorithm is based on GHT (the metric space part) and DRT and DDH techniques (the distributed part). The architecture of the distributed environment comprises network nodes (peers), which hold the objects, perform similarity queries on stored data and respond to them. Every peer is uniquely identified by its PID (Peer ID).
Every peer holds a bunch of buckets, which are used to physically store the objects. Each bucket has a unique identifier per peer called BID. Each peer has a GHT like structure that we will call address search tree (AST). It is used to route the queries through the distributed network.
AST is a slightly modified GHT. First, we have a different bucket association and the buckets are distributed among the peers. Moreover, the tree leaf nodes have either a PID, if the bucket is on another peer, or a BID, if the bucket is held on the current peer.
Each peer has its own "view" of the distributed structure represented by its AST. The view may be incomplete (in a way that some branches of the tree are missing), because any peer can split a bucket any time. This may cause sending requests to incorrect peers, but this is not a problem. Whenever such misaddressing occurs, the request is forwarded to the correct peer and the caller is informed using update message.
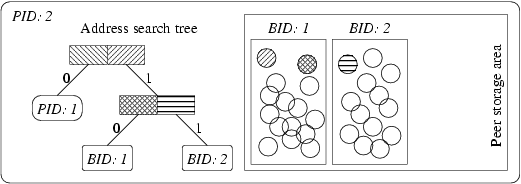
When a peer wants to insert a new object, it first consults its local AST, and it finds a leaf node containing a BID (in that case the inserted object is stored in the bucket BID located on the current peer, which must be split when an overflow occurs) or a PID. In the later case, the insert request must be sent to more appropriate peer PID. The same method is used when an insert request is received (through forwarding).
In order to perform a range search we again traverse the AST of the current peer. We obtain a set of PIDs and BIDs, this because, as explained, range query may follow both the subtrees of a node in AST. In this case, the query message is sent to all peers from the set of PIDs. All buckets from the set of BIDs on current peer are searched for matching objects.
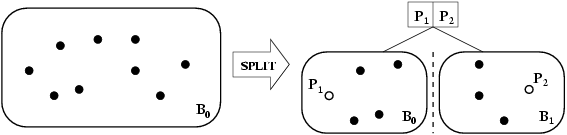
Since the bucket capacity is limited, it must be split when an overflow occurs. Suppose a bucket in the peer with PID j overflows, the splitting is performed in the three following steps. First, we create a new bucket on either the peer j or another active peer. Second, for the created bucket, we choose a pair of pivots and we update the AST. Finally, we move some objects from current bucket to the new one according to the new pivots.